# 浏览器渲染原理
过程包含 渲染进程 (主线程、合成线程、线程池)、 预解析进程 和 网络进程
# 解析 HTML
浏览器会开辟渲染进程、预解析进程和网络线程,预解析进程快速扫描并交给网络线程加载 js 和 css 文件,渲染进程会解析 HTML 字符串,解析成 DOM 树和 CSSOM 树这种容易操作的对象,也给 JS 提供了操作这两颗树的能力(document.body 和 document.styleSheets)。预解析进程加载和执行 JS 代码时,渲染进程会被阻塞,因为 JS 代码可能会操作 DOM 树和 CSSOM 树
解析 HTML 的结果是得到 DOM 树和 CSSOM 树。
# 样式计算
得到 DOM 树和 CSSOM 树之后,还需要知道每个 DOM 对应的样式,
渲染进程的主线程会遍历 DOM 中的每个节点,并计算他最终的样式,称之为Computed Style,也叫做合并DOM树和CSSOM树为渲染树
样式计算的结果是得到一颗渲染树,这一过程中,很多预设值会变成绝对值,比如red会变成rgb,相对单位会变成绝对单位
# 布局
布局阶段会遍历 DOM 树的每一个节点,计算每个节点的几何信息(节点的宽高、相对于包含块的位置)最后生成
布局树,由于display:none、匿名行盒、匿名块盒的原因,导致DOM树和布局树不是一一对应的
布局的结果是创建布局树
# 分层
主线程会使用一套复杂的策略对
布局树进行分层,分层的好处在于将来改变一个层之后,仅会对该层进行后续处理,从而提升效率。滚动条、transform、opacity、will-change等都会影响分层的结果
分层的结果是分层了布局树
# 生成绘制指令
主线程会为每一层单独生成绘制指令,用于描述这一层内容怎么画出来,类似于 canvas 中的画笔。
生成绘制指令的结果是:得到了绘制指令集
# 分块
得到
绘制指令集之后,主线程会将每个图层的绘制信息交给合成线程,剩下的工作将由合成线程完成。合成线程首先会对每个图层进行分块,将其划分为更多的小区域,合成线程会从线程池中拿出多个线程来完成分块工作。
# 光栅化
合成线程会将块信息交给 GPU 进程,以极高的速度完成光栅化。光栅化就是
将每个块变成位图,位图可以理解成内存里的一个二维数组,这个二维数组记录了每个像素点信息。GPU 进程会开启多个线程来完成光栅化,并且优先处理靠近视口区域的块。
光栅化的结果,就是一块一块的位图。
# 绘制
合成线程计算出每个位图的在屏幕上的位置,交给 GPU 进行最终实现。
注:光栅化阶段和绘制阶段也统称为:合成阶段,transform就在这一阶段被执行。
# 何为进程?
程序运行需要有它自己专属的内存空间,可以把这块内存空间简单的理解为进程
每个应用至少有一个进程,进程之间相互独立,即使要通信,也需要双方同意。

# 何为线程?
有了进程后,就可以运行程序的代码了。
运行代码的「人」称之为「线程」。
一个进程至少有一个线程,所以在进程开启后会自动创建一个线程来运行代码,该线程称之为主线程。
如果程序需要同时执行多块代码,主线程就会启动更多的线程来执行代码,所以一个进程中可以包含多个线程。

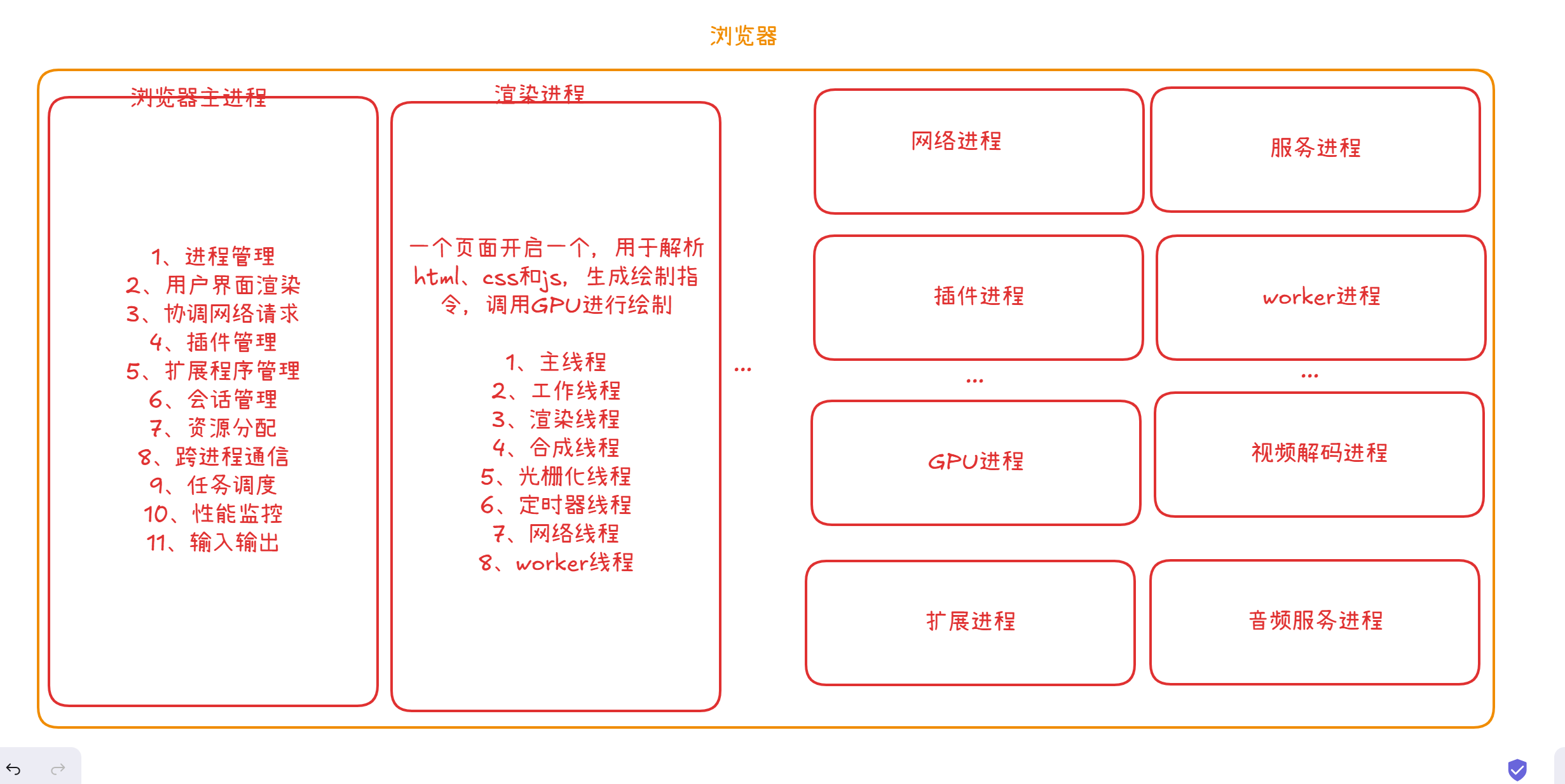
浏览器有哪些进程和线程?
浏览器是一个多进程多线程的应用程序
浏览器内部工作极其复杂。
为了避免相互影响,为了减少连环崩溃的几率,当启动浏览器后,它会自动启动多个进程。

可以在浏览器的任务管理器中查看当前的所有进程
其中,最主要的进程有:
# 浏览器进程
主要负责界面显示、用户交互、子进程管理等。浏览器进程内部会启动多个线程处理不同的任务。
# 网络进程
负责加载网络资源。网络进程内部会启动多个线程来处理不同的网络任务。
# 渲染进程
渲染进程启动后,会开启一个渲染主线程,主线程负责执行 HTML、CSS、JS 代码。
默认情况下,浏览器会为每个标签页开启一个新的渲染进程,以保证不同的标签页之间不相互影响。
将来该默认模式可能会有所改变,有兴趣的同学可参见 chrome 官方说明文档
渲染主线程是如何工作的?
渲染主线程是浏览器中最繁忙的线程,需要它处理的任务包括但不限于:
解析 HTML
解析 CSS
计算样式
布局
处理图层
每秒把页面画 60 次
执行全局 JS 代码
执行事件处理函数
执行计时器的回调函数
……
思考题:为什么渲染进程不适用多个线程来处理这些事情?
要处理这么多的任务,主线程遇到了一个前所未有的难题:如何调度任务?
比如:
我正在执行一个 JS 函数,执行到一半的时候用户点击了按钮,我该立即去执行点击事件的处理函数吗?
我正在执行一个 JS 函数,执行到一半的时候某个计时器到达了时间,我该立即去执行它的回调吗?
浏览器进程通知我 “用户点击了按钮”,与此同时,某个计时器也到达了时间,我应该处理哪一个呢?
……
渲染主线程想出了一个绝妙的主意来处理这个问题:排队

在最开始的时候,渲染主线程会进入一个无限循环
每一次循环会检查消息队列中是否有任务存在。如果有,就取出第一个任务执行,执行完一个后进入下一次循环;如果没有,则进入休眠状态。
其他所有线程(包括其他进程的线程)可以随时向消息队列添加任务。新任务会加到消息队列的末尾。在添加新任务时,如果主线程是休眠状态,则会将其唤醒以继续循环拿取任务
这样一来,就可以让每个任务有条不紊的、持续的进行下去了。
整个过程,被称之为事件循环(消息循环)
若干解释
# 何为异步?
代码在执行过程中,会遇到一些无法立即处理的任务,比如:
计时完成后需要执行的任务 —— setTimeout、setInterval。
网络通信完成后需要执行的任务 – XHR、Fetch。
用户操作后需要执行的任务 – addEventListener。
如果让渲染主线程等待这些任务的时机达到,就会导致主线程长期处于「阻塞」的状态,从而导致浏览器「卡死」。

渲染主线程承担着极其重要的工作,无论如何都不能阻塞!
因此,浏览器选择异步来解决这个问题

使用异步的方式,渲染主线程永不阻塞
面试题:如何理解 JS 的异步?
参考答案:
JS 是一门单线程的语言,这是因为它运行在浏览器的渲染主线程中,而渲染主线程只有一个。
而渲染主线程承担着诸多的工作,渲染页面、执行 JS 都在其中运行。
如果使用同步的方式,就极有可能导致主线程产生阻塞,从而导致消息队列中的很多其他任务无法得到执行。这样一来,一方面会导致繁忙的主线程白白的消耗时间,另一方面导致页面无法及时更新,给用户造成卡死现象。
所以浏览器采用异步的方式来避免。具体做法是当某些任务发生时,比如计时器、网络、事件监听,主线程将任务交给其他线程去处理,自身立即结束任务的执行,转而执行后续代码。当其他线程完成时,将事先传递的回调函数包装成任务,加入到消息队列的末尾排队,等待主线程调度执行。
在这种异步模式下,浏览器永不阻塞,从而最大限度的保证了单线程的流畅运行。
JS 为何会阻碍渲染?
先看代码
var h1 = document.querySelector('h1'); | |
var btn = document.querySelector('button'); | |
// 死循环指定的时间 | |
function delay(duration) { | |
var start = Date.now(); | |
while (Date.now() - start < duration) {} | |
} | |
btn.onclick = function () { | |
h1.textContent = 'hello world!'; | |
delay(3000); | |
}; |
# 点击按钮后,会发生什么呢?
<见具体演示>
任务有优先级吗?
任务没有优先级,在消息队列中先进先出
但消息队列是有优先级的
根据 W3C 的最新解释:
每个任务都有一个任务类型,同一个类型的任务必须在一个队列,不同类型的任务可以分属于不同的队列。
在一次事件循环中,浏览器可以根据实际情况从不同的队列中取出任务执行。
浏览器必须准备好一个微队列,微队列中的任务优先所有其他任务执行
https://html.spec.whatwg.org/multipage/webappapis.html#perform-a-microtask-checkpoint随着浏览器的复杂度急剧提升,W3C 不再使用宏队列的说法
在目前 chrome 的实现中,至少包含了下面的队列:
延时队列:用于存放计时器到达后的回调任务,优先级「中」
交互队列:用于存放用户操作后产生的事件处理任务,优先级「高」
微队列:用户存放需要最快执行的任务,优先级「最高」
添加任务到微队列的主要方式主要是使用 Promise、MutationObserver
例如:
// 立即把一个函数添加到微队列
Promise.resolve ().then (函数)
浏览器还有很多其他的队列,由于和我们开发关系不大,不作考虑
# 面试题:
# 阐述一下 JS 的事件循环
参考答案:
事件循环又叫做消息循环,是浏览器渲染主线程的工作方式。
在 Chrome 的源码中,它开启一个不会结束的 for 循环,每次循环从消息队列中取出第一个任务执行,而其他线程只需要在合适的时候将任务加入到队列末尾即可。
过去把消息队列简单分为宏队列和微队列,这种说法目前已无法满足复杂的浏览器环境,取而代之的是一种更加灵活多变的处理方式。
根据 W3C 官方的解释,每个任务有不同的类型,同类型的任务必须在同一个队列,不同的任务可以属于不同的队列。不同任务队列有不同的优先级,在一次事件循环中,由浏览器自行决定取哪一个队列的任务。但浏览器必须有一个微队列,微队列的任务一定具有最高的优先级,必须优先调度执行。
# JS 中的计时器能做到精确计时吗?为什么?
参考答案:
不行,因为:
计算机硬件没有原子钟,无法做到精确计时
操作系统的计时函数本身就有少量偏差,由于 JS 的计时器最终调用的是操作系统的函数,也就携带了这些偏差
按照 W3C 的标准,浏览器实现计时器时,如果嵌套层级超过 5 层,则会带有 4 毫秒的最少时间,这样在计时时间少于 4 毫秒时又带来了偏差
受事件循环的影响,计时器的回调函数只能在主线程空闲时运行,因此又带来了偏差
# URL 到页面渲染的全程
整体流程
用户在某个标签页输入 URL 并回车后,浏览器主进程会新开一个网络线程,发起 HTTP 请求
浏览器检查自带的 “预加载 HSTS(HTTP 严格传输安全)” 列表,这个列表里包含了那些请求浏览器只使用 HTTPS 进行连接的网站
如果网站在这个列表里,浏览器会使用 HTTPS 而不是 HTTP 协议,否则,最初的请求会使用 HTTP 协议发送
注意,一个网站哪怕不在 HSTS 列表里,也可以要求浏览器对自己使用 HSTS 政策进行访问。浏览器向网站发出第一个 HTTP 请求之后,网站会返回浏览器一个响应,请求浏览器只使用 HTTPS 发送请求。然而,就是这第一个 HTTP 请求,却可能会使用户受到 downgrade attack 的威胁,这也是为什么现代浏览器都预置了 HSTS 列表。
浏览器会进行 DNS 查询,通过 DNS 查询将域名解析为 IP 地址
检查域名是否在缓存当中
DNS 缓存:浏览器缓存 ——>hosts 文件 ——> 路由器缓存 ——> 网络服务商缓存 ——> 根域名服务器缓存
浏览器获得 IP 地址后,向服务器请求建立 TCP 连接
# TCP 三次握手
客户端选择一个初始序列号 (ISN),将设置了 SYN 位的封包发送给服务器端,表明自己要建立连接并设置了初始序列号
*** 服务器端接收到 SYN 包,如果它可以建立连接:*** 服务器端选择它自己的初始序列号服务器端设置 SYN 位,表明自己选择了一个初始序列号服务器端把 (客户端 ISN + 1) 复制到 ACK 域,并且设置 ACK 位,表明自己接收到了客户端的第一个封包
*** 客户端通过发送下面一个封包来确认这次连接:*** 自己的序列号 + 1 接收端 ACK+1 设置 ACK 位
*** 数据通过下面的方式传输:*** 当一方发送了 N 个 Bytes 的数据之后,将自己的 SEQ 序列号也增加 N 另一方确认接收到这个数据包(或者一系列数据包)之后,它发送一个 ACK 包,ACK 的值设置为接收到的数据包的最后一个序列号
*** 关闭连接时:*** 要关闭连接的一方发送一个 FIN 包另一方确认这个 FIN 包,并且发送自己的 FIN 包要关闭的一方使用 ACK 包来确认接收到了 FIN
# TLS 握手
客户端发送一个 ClientHello 消息到服务器端,消息中同时包含了它的 Transport Layer Security (TLS) 版本,可用的加密算法和压缩算法。
服务器端向客户端返回一个 ServerHello 消息,消息中包含了服务器端的 TLS 版本,服务器所选择的加密和压缩算法,以及数字证书认证机构(Certificate Authority,缩写 CA)签发的服务器公开证书,证书中包含了公钥。客户端会使用这个公钥加密接下来的握手过程,直到协商生成一个新的对称密钥
客户端根据自己的信任 CA 列表,验证服务器端的证书是否可信。如果认为可信,客户端会生成一串伪随机数,使用服务器的公钥加密它。这串随机数会被用于生成新的对称密钥
服务器端使用自己的私钥解密上面提到的随机数,然后使用这串随机数生成自己的对称主密钥
客户端发送一个 Finished 消息给服务器端,使用对称密钥加密这次通讯的一个散列值
服务器端生成自己的 hash 值,然后解密客户端发送来的信息,检查这两个值是否对应。如果对应,就向客户端发送一个 Finished 消息,也使用协商好的对称密钥加密
从现在开始,接下来整个 TLS 会话都使用对称秘钥进行加密,传输应用层(HTTP)内容
HTTP 的长连接与短连接与 2.0
HTTP/1.0 默认使用的是短连接。也就是说,浏览器每请求一个静态资源,就建立一次连接,任务结束就中断连接。
HTTP/1.1 默认使用的是长连接。长连接是指在一个网页打开期间,所有网络请求都使用同一条已经建立的连接。当没有数据发送时,双方需要发检测包以维持此连接。长连接不会永久保持连接,而是有一个保持时间。实现长连接要客户端和服务端都支持长连接。
长连接的优点:TCP 三次握手时会有 1.5 RTT 的延迟,以及建立连接后慢启动(slow-start)特性,当请求频繁时,建立和关闭 TCP 连接会浪费时间和带宽,而重用一条已有的连接性能更好。
长连接的缺点:长连接会占用服务器的资源。
HTTP 2.0 的三大特性是头部压缩、服务端推送、多路复用。
HTTP 1.1 允许通过同一个连接发起多个请求。但是由于 HTTP 1.X 使用文本格式传输数据,服务端必须按照客户端请求到来的顺序,串行返回数据。此外,HTTP 1.1 中浏览器会限制同时发起的最大连接数,超过该数量的连接会被阻塞。
HTTP 2 引入了多路复用,允许通过同一个连接发起多个请求,并且可以并行传输数据。HTTP 2 使用二进制数据帧作为传输的最小单位,每个帧标识了自己属于哪个流,每个流对应一个请求。服务端可以并行地传输数据,而接收端可以根据帧中的顺序标识,自行合并数据。
在 HTTP 1.1 中,由于浏览器限制每个域名下最多同时有 6 个请求,其余请求会被阻塞,因此我们通常使用多个域名(比如 CDN)来提高浏览器的下载速度。HTTP 2 就不再需要这样优化了。
同理,在 HTTP 1.1 中,我们会将多个 JS 文件、CSS 文件等打包成一个文件,将多个小图片合并为雪碧图,目的是减少 HTTP 请求数。HTTP 2 也不需要这样优化了。
浏览器向服务器发起 HTTP 请求
服务器处理请求,返回 HTTP 响应
浏览器的渲染进程解析并绘制页面
如果遇到 JS/CSS/ 图片 等静态资源的引用链接,重复上述过程,向服务器请求这些资源
browser
# TCP 四次挥手
流程:
客户端应用程序发出释放连接的报文段,并停止发送数据,主动关闭 TCP 连接。客户端主机发送释放连接的报文段,报文段中首部 FIN 位置为 1 ,不包含数据,序列号位 seq = u,此时客户端主机进入 FIN-WAIT-1 (终止等待 1) 阶段。
服务器主机接受到客户端发出的报文段后,即发出确认应答报文,确认应答报文中 ACK = 1,生成自己的序号位 seq = v,ack = u + 1,然后服务器主机就进入 CLOSE-WAIT (关闭等待) 状态。
客户端主机收到服务端主机的确认应答后,即进入 FIN-WAIT-2 (终止等待 2) 的状态。等待客户端发出连接释放的报文段。
这时服务端主机会发出断开连接的报文段,报文段中 ACK = 1,序列号 seq = v,ack = u + 1,在发送完断开请求的报文后,服务端主机就进入了 LAST-ACK (最后确认) 的阶段。
客户端收到服务端的断开连接请求后,客户端需要作出响应,客户端发出断开连接的报文段,在报文段中,ACK = 1, 序列号 seq = u + 1,因为客户端从连接开始断开后就没有再发送数据,ack = v + 1,然后进入到 TIME-WAIT (时间等待) 状态,请注意,这个时候 TCP 连接还没有释放。必须经过时间等待的设置,也就是 2MSL 后,客户端才会进入 CLOSED 状态,时间 MSL 叫做最长报文段寿命(Maximum Segment Lifetime)。
服务端主机收到了客户端的断开连接确认后,就会进入 CLOSED 状态。因为服务端结束 TCP 连接时间要比客户端早,而整个连接断开过程需要发送四个报文段,因此释放连接的过程也被称为四次挥手。
关闭连接的方式通常有两种,分别是 RST 报文关闭和 FIN 报文关闭。
如果进程异常退出了,内核就会发送 RST 报文来关闭,它可以不走四次挥手流程,是一个暴力关闭连接的方式。
TIMEWAIT
TIME_WAIT 状态相当于是客户端在关闭前的最后一个状态,它是一种主动关闭的状态;而 LAST_ACK 是服务端在关闭前的最后一个状态,它是一种被动打开的状态。
需要 TIME_WAIT 状态的原因:
防止延迟的数据段被其他使用相同源地址、源端口、目的地址以及目的端口的 TCP 连接收到;
保证 TCP 连接的远程被正确关闭,即等待被动关闭连接的一方收到 FIN 对应的 ACK 消息;
为什么是 2 MSL 的时长呢?
这其实是相当于至少允许报文丢失一次。比如,若 ACK 在一个 MSL 内丢失,这样被动方重发的 FIN 会在第 2 个 MSL 内到达,TIME_WAIT 状态的连接可以应对。
客户端受端口资源限制:如果客户端 TIME_WAIT 过多,就会导致端口资源被占用,因为端口就 65536 个,被占满就会导致无法创建新的连接;
服务端受系统资源限制:由于一个四元组表示 TCP 连接,理论上服务端可以建立很多连接,服务端确实只监听一个端口,但是会把连接扔给处理线程,所以理论上监听的端口可以继续监听。但是线程池处理不了那么多一直不断的连接了。所以当服务端出现大量 TIME_WAIT 时,系统资源被占满时,会导致处理不过来新的连接;
Linux 提供了 tcp_max_tw_buckets 参数,当 TIME_WAIT 的连接数量超过该参数时,新关闭的连接就不再经历 TIME_WAIT 而直接关闭:
同时关闭
由于 TCP 是全双工的协议,所以是会出现两方同时关闭连接的现象,也就是同时发送了 FIN 报文。当客户端与服务端同时发起 FIN 报文请求关闭连接时,都认为自己是主动方,所以都进入了 FIN_WAIT1 状态,FIN 报文的重发次数仍由 tcp_orphan_retries 参数控制。接下来,双方在等待 ACK 报文的过程中,都等来了 FIN 报文。这是一种新情况,所以连接会进入一种叫做 CLOSING 的新状态,它替代了 FIN_WAIT2 状态。接着,双方内核回复 ACK 确认对方发送通道的关闭后,进入 TIME_WAIT 状态,等待 2MSL 的时间后,连接自动关闭。