# 软件生命周期:
# 架构流程图

# 复杂项目通用方案
# 业务的复杂度
- 交互的复杂性
- 数据结构和状态的复杂性
- 多项目互相依赖的复杂性
- 打包
- 性能优化
- 第三方库的使用和调研以及二次开发
# 流程的复杂度
- git flow
- lint 工具
- 单元测试
- commit 信息
- PR revirew
- CI / CD
# CI / CD 的概念
业务组件库的开发和发布是随着一些列任务进化的:
- 本地 commit 钩子函数完成 commit 验证
- 代码 push 到远端之后
- 跑特定的 test(不仅仅是本机的 unit test,也可能有时间很长的 E2E test)
- test 通过之后检查是否有新的 tag,如果有就自动 publish 一个新的版本
- 甚至还有更多,自动部署文档站点等等。
这些任务如果手动操作,就费时费力,所以需要自动化进行。
# CI(Continuous integration)持续集成
持续集成是指频繁地将代码集成到主干,一旦开发人员对应用所做的更改被合并,系统就会通过自动构建应用并运行不同级别的自动化测试(通常是单元测试和集成测试)来验证这些更改,确保这些更改没有对应用造成破坏。
作用有:
- 快速发现错误
- 防止分支大幅偏离主干
持续集成的目的就是让产品可以快速迭代,同时保持高质量。
# CD(Continuous Delivery)持续交付
持续交付是指频繁地将软件的新版本,交付给质量团队或者用户,以供评审。
# CD(Continuous Deployment)持续部署
持续部署是持续交付的下一步,指的是代码通过评审以后,自动部署到生产环境。
# CI / CD 两大服务:
- github actions
- travis-ci
# 列表排序解决方案
列表排序原理:
<template> | |
<div> | |
<ul class="ul" @drop="onDrop"> | |
<li | |
v-for="(item,index) in list" | |
:data-index="index" | |
:key="item.id" | |
@dragover="onDragover($event,index)" | |
@dragstartart="dragstart($event,index)" | |
@dragenter="dragenter($event,index)" | |
draggable="true" | |
:class="[item.id==currentLi?'glost':'']" | |
><!--swig0--></li> | |
</ul> | |
</div> | |
</template> | |
<script setup> | |
/*eslint-disable*/ | |
import { ref } from "vue"; | |
import {arrayMoveImmutable} from 'array-move'; | |
let currentLi = ref(1); | |
let index = ref(1); | |
const list = ref( | |
[ | |
{id:1,name:'列表1'}, | |
{id:2,name:'列表2'}, | |
{id:3,name:'列表3'}, | |
{id:4,name:'列表4'}, | |
{id:5,name:'列表5'}, | |
] | |
) | |
const dragstart = (e,inde)=>{ | |
currentLi.value = inde; | |
} | |
const dragenter = (e,ind)=>{ | |
if(ind != currentLi.value){ | |
list.value = arrayMoveImmutable(list.value,ind,currentLi.value) | |
currentLi.value = ind; | |
} | |
} | |
const onDrop = (e)=>{ | |
console.log(e.target.dataset.index,'drop'); | |
list.value = arrayMoveImmutable(list.value,index.value,currentLi.value) | |
console.log(list.value); | |
} | |
const onDragover = (e,inde)=>{ | |
e.preventDefault(); | |
index.value = inde; | |
} | |
</script> | |
<style scoped> | |
.ul>li{ | |
width: 100%; | |
height: 50px; | |
border: 1px solid red; | |
} | |
.glost{ | |
box-shadow: 10px 10px 3px 3px gray; | |
} | |
</style> |
列表排序常用工具包:
- vue-draggable
- sortable.js
- array-move.js
# 拖动改变位置原理
通过监听 mousedown 和 mousemove 事件,用 element.getBoundingClientRect 方法获得 x 和 y,left 和 top 等属性,改变对应元素的 top 和 left 属性。
# 拖动改变大小原理
设置边框元素,边框元素的四个角添加圆点元素,监听 mousedown 事件和 mousemove 事件,并将最新的坐标赋值给元素的尺寸大小。
# 快捷键实现原理
好用的快捷键第三方库:Hotkeys.js
事件原理:keydown 事件的监听,通过 event.key 判断是那个快捷键,从而执行对应的操作。
# 撤销重做原理
维护一个固定长度的 histories 数组和 historyIndex 指针,每次修改的时候添加一条记录(标识操作类型和数据)。回滚时改变 historyIndex 指针。
# 右键菜单原理
在需要显示的区域拦截默认的右键点击事件,判断是否点击在组件元素上(通过 event.target),显示一个自定义菜单,其中包括操作项,显示在鼠标的位置(event.clientX 和 event.clientY),点击完成操作,通过 display:none 隐藏。
# 自动保存实现方案
- 定时保存(语雀)
- 实时保存(石墨)
实现原理:添加 isDrity 字段标记数据是否有修改,当修改时将 isDirty 设置为 true,根据 isDIrty 的值设置定时器,定时触发保存逻辑。
# DOM 元素截图实现方案
工具包:html2canvas
实现原理:
根据 DOM 元素的 styles 样式,通过 svg 的 foreignObject 元素引入 XML 命名空间的元素,然后创建一个 image 标签,将 svg 通过 url.createObjectURL 方法创建一个路径赋值给一个 image 标签的 src 属性,通过 canvas 画笔 的 drawImage 方法将 image 图片绘制到 canvas 画布上。
实现流程:
- style 设置 DOM 样式
- svg 引入 DOM
- createObjectURL 创建 url 路径
- 将 url 复制到 image 标签的 src
- canvas 的 drawImage 将 image 图片绘制到 canvas 画布上
const data = | |
"<svg xmlns='http://www.w3.org/2000/svg'width='400px'height='40 | |
"<foreignabject width='100%'height='100%'>"+ | |
"<div xmlns='http://ww.w3.org/1999/xhtml'>" | |
element.innerHTML+ | |
"</div>"+ | |
"</foreignobject>" + | |
"</svg>" | |
const svg = new Blob([data],{type:"image/svg+xml;charset=utf-8"}); | |
const url = URL.createobjectURL(svg) | |
const image = new Image() | |
image.src = url | |
image.addEventListener('load',()=>{ | |
const ctx =anvas.getContext('2d'); | |
if (ctx){ | |
ctx.drawImage(image,0,0) | |
} | |
}) |
# 二维码生成方案
- 工具包:node-qrcode
- ts 项目中需要安装额外的定义文件。
简单原理:将数据变为二进制,然后通过 canvas 将二进制变为图像。
<body> | |
<canvas id="qrcode" width="128" height="128"></canvas> | |
<script> | |
// 将字符串转为二进制形式 | |
function toBianary(str){ | |
let res = ''; | |
for(let i=0;i<str.length;i++){ | |
let charCode = str.charCodeAt(i); | |
let binaryCharCode = charCode.toString(2); | |
res += binaryCharCode.padStart(8,'0'); | |
} | |
return res; | |
} | |
// 绘制 | |
function drawQRCode(text, canvas) { | |
var context = canvas.getContext("2d"); | |
// 绘制黑白像素点 | |
for (var i = 0; i < text.length; i++) { | |
var row = Math.floor(i / canvas.width); | |
var col = i % canvas.width; | |
var color = text.charAt(i) === "1" ? "#000000" : "#FFFFFF"; | |
context.fillStyle = color; | |
context.fillRect(col, row, 1, 1); | |
} | |
} | |
var qrcodeCanvas = document.getElementById("qrcode"); | |
drawQRCode(toBianary('https://dmqweb.cn'), qrcodeCanvas); // 示例:绘制一个简单的二维码 | |
</script> |
# 复制功能实现原理
- 工具包:clipboard.js
- 自带 type 定义文件
实现原理:
方案一:document.execCommand () 方法。内置一系列功能,包括复制文本(但前提是需要选中文本),可以使用不可见元素迂回。
方案二:Clipboard API( navigator.clipboard ),但是对于浏览器兼容性有待加强。
# 下载文件原理
- 工具包:FileSaver.js(小文件)
- StreamSaver.js(大文件)
方案一:超链接 a 标签添加 download 属性,属性值为文件名,rel 属性设置打开页面的具体实现细节。(但前提是 href 属性为当前同源情况下。)
方案二:通过 axios 请求到图片地址,通过 URL.createObjectURL 创建为一个与 document 相绑定的地址,赋值给 a 标签即可。(不要忘记使用 URL.revokeObjectURL 将创建的地址移除。)
方案三:通过 FileReader.readAsDataURL,创建一个 FileReader 实例,使用 readAsDataURL 读取对象返回一段 base64 格式的字符串,监听 reader 实例的 onload 事件,创建 a 标签将 reader.result 赋值给 a 标签的 href 属性。
downloadFile:function(data,fileName){ | |
const reader = new FileReader() | |
// 传入被读取的 blob 对象 | |
reader.readAsDataURL(data) | |
// 读取完成的回调事件 | |
reader.onload = (e) => { | |
let a = document.createElement('a') | |
a.download = fileName | |
a.style.display = 'none' | |
// 生成的 base64 编码 | |
let url = reader.result | |
a.href = url | |
document.body.appendChild(a) | |
a.click() | |
document.body.removeChild(a) | |
} | |
} |
终极解决方案:由于通过 URL.createObjectURL 和 FileReader 都会先将数据保存到内存中,业务中经常需要后端验证 token 之后才能拿到文件,不能直接使用 a 标签。因此实际中可以先发送 ajax 请求验证 token,验证之后颁发一个过期时间短的 cookie,之后使用 a 标签进行下载即可。但是同样会受到 a 标签 download 属性跨域请求的限制。
# 应用部署的流程
构建
Javascript 语言本身是不需要编译的。
但是现代的前端项目使用的语言和或者的模块系统都无法在浏览器中使用,都需要使用特定的
bundler 将源代码最终转换为浏览器支持的 Javascript 代码。
不同的环境:
开发环境 (development) :本地的测试环境
测试环境 (test 或者 staging):线上的测试环境
生产环境(production):线上的生产环境
生产和开发环境的区别
开发环境会添加丰富的错误提示,可以使用 mock server 或者本地后端环境添加各种便利的功能 - 比如 hot reload, 自动刷新,不太关心静态资源的大小,最好提供最丰富的调试信息 (sourcemap) 等。
生产环境
- 稳定是最重要的原则
- 速度是第一要务
生产环境和测试环境的区别
- 高度相似
- 使用的后端服务不一样
环境变量设置(按优先级)
- 跨平台设置环境变量工具包:cross-env
- 命令中添加环境变量(平台限制)
- 环境变量文件中配置
在项目根目录中放置下列文件来指定环境变量
- .env #在所有的环境中被载入
- .env.local #在所有的环境中被载入,但会被 git 忽略
- env.[mode] #只在指定的模式中被载入
- env.[mode].local #只在指定的模式中被载入,但会被 git 忽略
# webpack 构建优化
# Bundler:
将浏览器不支持的模块进行编译,转换,
合并最后生成的代码可以在浏览器端良好的运行的工具。
# Loaders:
loader 用于对模块的源代码进行转换。loader 可以使你在 import 或 "Ioad (加载)" 模块时预处理文件。
多个 Loader
module.rules 允许你在 webpack 配置中指定多个 loader。这种方式是展示 loader 的一种简明方式,并且有助于使代码变得简洁和易于维护。
webpack 中 loader 配置:
const path = require('path') | |
module.exports = { | |
entry:'./main.js', | |
output:{ | |
path:path.resolve(dirname,'dist'), | |
filename:bundle.js', | |
} | |
}, | |
module:{ | |
rules:[ | |
{ | |
test:/\.css$/, | |
use: [ | |
loader:'style-loader'}, // 先写的 loader 后执行。 | |
loader:'css-loader'} | |
] | |
}] | |
} | |
} |
# 原理
webpack 中 loader 原理:
在 webpack.config.js 的 module 字段的 rules 数组中进行配置:添加一个对象标识一个独立的匹配项,test 字段使用正则表示匹配的文件名,use 数组表示对应文件需要执行的 loader,webpack 在打包时会将文件内容传入并执行对应的 loader(是一个函数),执行 loader 函数后的返回值就是普通的 JS 模块代码,因此 webpack 中的 loader 通常需要进行两次 module.exports。
// 手写一个 md 文件的 loader | |
const marked = require('marked'); // 第三方库,用于将 md 转为 html | |
const utils = require('loader-utils') // 官方库,用于获取用户配置 loader 时传入的参数 | |
const markdownLoader = (source) => { | |
const options = utils.getOptions(this); | |
const html = marked(source , options); | |
return `module.exports = ${JSON.stringify(html)}`; | |
} | |
module.exports = markdownLoader; |
配置:
const path = require('path') | |
module.exports = { | |
entry:'./main.js', | |
output:{ | |
path:path.resolve(dirname,'dist'), | |
filename:bundle.js', | |
} | |
}, | |
module:{ | |
rules:[ | |
{ | |
test:/\.css$/, | |
use: [ | |
{ loader:'style-loader' }, // 先写的 loader 后执行。 | |
{ loader:'css-loader' } | |
] | |
}, | |
{ | |
test:/\.md$/, | |
use: [ | |
{ loader: './markdonwn-loader',options:{ headerIds:false } } // 其中 options 是给 loader 函数传入的第二个参数,loader 中可以使用 loader-utils 官方三方库进行接受 | |
] | |
}] | |
} | |
} |
多个 Loader 串联
最后的 loader 最早调用,将会传入原始资源内容。
第一个 loader 最后调用,期望值是传出 JavaScript 和 source map (可选)。
中间的 loader 执行时,会传入前一个 loader 传出的结果。
将 markdown 转换为 html:turndown
地址:https://github.om/domchristie/turndown
# plugins:
https://webpack.docschina.org/concepts/plugins/
插件是 webpack 的支柱功能。webpack 自身也是构建开你在 webpack 配置中用到的相同的插件系统之上!插件目的在于解决 loader 无法实现的其他事。(我自己的理解,loader 解决的是各种不同资源的问题,plugins 更多解决的是项目整体的事情)
const path = require('path'); | |
const HtmlWebpackPlugin = require('html-webpack-plugin'); | |
module.exports = { | |
entry:'./main.js', | |
output:{ | |
path:path.resolve(dirname,'dist'), | |
filename:bundle.js', | |
} | |
}, | |
module:{ | |
rules:[ | |
{ | |
test:/八.css$/, | |
use: [ | |
loader:'style-loader'}, // 先写的 loader 后执行。 | |
loader:'css-loader'} | |
] | |
}] | |
}, | |
plugins:[ | |
new BundlesizeWebpackPlugin( { sizeLimit:3 } ) // 自己手写的插件(如下) | |
new webpack.ProgressPlugin(), // 显示打包过程(webpack 内置插件) | |
new HtmlwebpackPlugin(), | |
] | |
} |
# 原理
webpack 中 plugins 原理:
webpack 执行时会将 plugins 字段中的插件实例取出并将 webpack 实例传入并执行其 apply 方法,通过 webpack 实例的 hooks 中的方法我们可以操控对应的钩子函数。
官方的教程:https://webpack.js.org/contribute/writing-a-plugin/
插件的格式
一个 JavaScript 函数或 JavaScript 类 ,在它原型上定义的 apply 方法,会在安装插件时被调用,并被 webpack compiler 调用一次。指定一个触及到 webpack 本身的事件钩子,即 hooks, 用于特定时机处理额外的逻辑
Compiler Hooks 列表
https://webpack.is.org/api/compiler-hooks/
// 手写一个 webpack 插件,打包文件超出限制时,报错。 | |
const { resolve } = require('path'); | |
const { statSync } = require('fs'); //fs 模块中同步读取文件信息 | |
class BundlesizeWebpackPlugin { | |
constructor(options) { | |
this.options = options; | |
} | |
apply(compiler) { | |
// 获取到传入的参数 | |
const { sizeLimit } = this.options; | |
compiler.hooks.compile.tap('BundleSizePlugin',(compilationParams)=>{ // 编译时钩子,参数是参数 | |
console.log('compile阶段',compilationParams); | |
}) | |
compiler.hooks.done.tap('BundleSizePlugin',(stats)=>{ // 结束时钩子,参数是打包后的信息。 | |
console.log('done',stats); | |
// 拿到打包后文件的路径和文件名 | |
const { path , filename } = stats.compilation.outputOptions; | |
// 拼接成文件路径 | |
const bundlePath = resolve(path,filename); | |
// 获取到文件 size | |
const { size } = statSync(bundlePath); | |
const bundleSize = size / 1024; | |
if(bundleSize < sizeLimit) { | |
console.log('Safe:Bundle-Size',bundleSize,'\n Size Limit:',sizeLimit); | |
}else{ | |
console.error('Unsafe:Bundle-Size',bundleSize,'\n Size Limit:',sizeLimit); | |
} | |
}) | |
} | |
} | |
module.exports = BundlesizeWebpackPlugin; |
# 总结
Loaders 关注代码中的单个资源,Plugins 关注整体流程,可以接触到 webpack 构建流程中的
各个阶段并劫持做一些代码处理。
# node 后端框架
# Node.js 后端框架调研
后端框架应该注意的三大问题
路由 Routes
请求 Request
响应 Response
# Express
官方网址:[https:l/expressis.com (https:expressis.com)
安装
官方网址:[https://expressis.com/zh-cn/starter/installing.html](https:l/expressjs.com/zh-
cn/starter/installing.html)
使用生成器安装,可以自动生成一系列的脚手架代码:[https:/expressjs.com/zh
cn/starter/generator.htmll(https://expressis.com/zh-cn/starter/generator.html)
优点
快速简单、易上手
缺点
- 路由响应中,很可能有:从外部请求数据的服务,有验证路由的请求参数,返回特定的格式。
- 所有逻辑不分青红皂白的写在一起!很容易产生冗长的难以维护的代码。
- 一些大型必备的模块,如第三方服务初始化,安全,日志都没有明确的标准。
Express 中间件:
Express 是一个基于中间件的框架,其余任务都会在中间件中执行,中间件是一个队列结构,先写入的任务先执行,中间件的写法是:app.use (),当调用中间件时,会向传入的函数中传入 req,res 和 next 函数。
中间件可以完成的任务
- 执行任何代码。
- 对请求和响应对象进行更改。
- 结束请求 / 响应循环。
- 调用堆栈中的下一个中间件。
# Koa2
官网地址:[https:I/koajs.com (https:/koajs.com)
Koa2 和 Express 的区别
- 使用 Promise (async,await) 代替 callback (node>v7.6.0)
- 使用 ctx (上下文对象) 封装 req (Request) 和 res (Response), 以及一些常用的功能。
- 完全不同的中间件机制
- 更轻量级,没有捆绑任何中间件
- 官方文章:https://github.com/koajs/koa/blob/naster/docs/koa-vs-express.md
Koa2 中间件:
- Koa2 中间件,由 Express 的队列模型(同步)转变为洋葱模型,当程序运行到
await next()的时候就会暂停当前程序,进入下一个中间件,处理完之后才会仔回过头来继续处理。 - Koa2 洋葱模型解决的问题就是一个中间件可以调用其他中间件执行后,再继续自己的操作,Express 框架中 next () 执行后就直接到下一个中间件操作,无法退回。
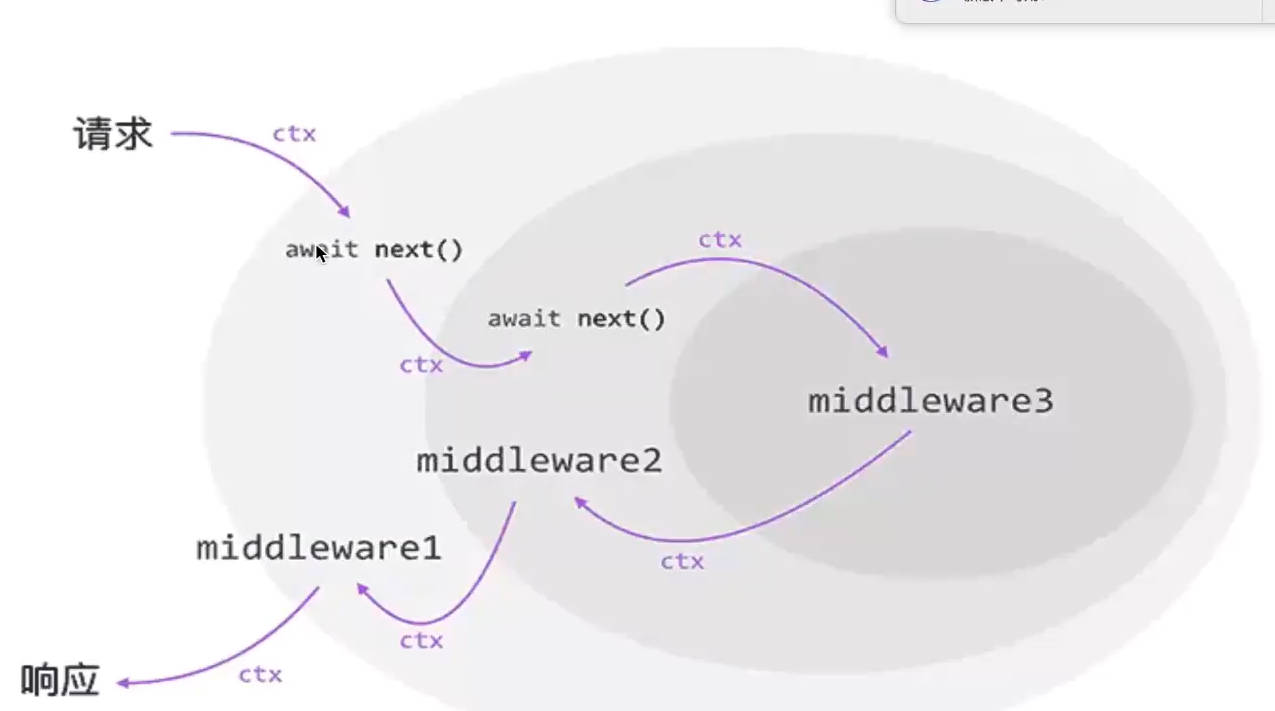
代码示例:
const Koa = require('koa'); | |
const app = new Koa(); | |
const PORT = 3000; | |
app.use(async (ctx, next)=>{ | |
console.log(1) | |
await next(); | |
console.log(1) | |
}); | |
app.use(async (ctx, next) => { | |
console.log(2) | |
await next(); | |
console.log(2) | |
}) | |
app.use(async (ctx, next) => { | |
console.log(3) | |
}) | |
app.listen(PORT); | |
console.log(`http://localhost:${PORT}`); |
Koa2 特点:
- 响应机制的不同
- Express: 我们直接操作的是 res 对象,直接 res.send 之后就立即响应了。
- Koa2: 数据的响应是通过 ctx.body 进行设置,注意这里仅是设置并没有立即响应,而是在所有的中间件结束之后做了响应。
** 缺点:**Koa2 在使用上有一定的缺点,因为太过于轻量使得在使用时需要手动处理很多操作,可以使用基于 Koa2 的上层框架(如:egg.js)
# egg.js
Express 和 Koa2 的不足
- 简单而且扩展性强,适合个人的比较小的项目
- 没有约定,对于统一维护和开发非常不利
对于后端框架的需求
- 需要有一套优秀的统一的约定或者架构进行开发
- 有丰富的扩展机制和可定制性
- Typescript 支持
egg.js
- 地址:[https:l/eggis.org/zh-cnI (https:l/eggjs.org/zh-cn) (基于 Koa2)
- 阿里大厂出品,维护有保障。国内开发者开发,中文文档质量有保证。
- 约定优于配置,按照一套统一的约定进行应用开发。
- 一个插件只做一件事,高度可扩展的插件机制
- 支持 Typescript
//nodejs版本10以上 | |
npm init egg --type=ts | |
npm install | |
npm run dev |
egg.js 概念:
Application - 全局应用对象,只有一个实例。
Context - 上下文对象,每次请求生成一个实例。
Request - 请求对象,来自 Koa。
Response - 响应对象,来自 Koa 的一个新的对象。
Helper - 用来提供一些实用的 utility 函数。框架内置了几个简单的 Helper 函数。
# Nest.js
- 地址:https:/docs.nestjs.com
- 内置并且完全支持 Typescript
- 开箱即用的应用程序架构
- 可扩展,松散耦合
- 大量采用了装饰器的写法 Nest.js 装饰器
# vue.config.js
个性化构建结果 - vue.config,js
在基础的配置上,自定义构建的结果 - 可以使用 vue.config.js
文档地址:https:l/cli.vuejs.org/zh/config#vue-config-js
简介两个字段
PublicPath - 部署应用包时的基本 URL, 这个配置对应的是 webpack 的 PublicPath 属性,默认值为 '/',Vue CLI 会假设你的应用是被部署在一个域名的根路径上 https://abc.com/。可以设置为子路径 - 如果你的应用被部署在 https:abc,com/sub/ 那么就设置为 '/sub',可以设置为 CDN 路径 - 在我们的应用中,最后静态资源是要全部上传到 CDN 的,(脚手架自动完成),所以这里可以设置为一个 cDN 域名 -'https:l/oss.imooc-Iego.com/editor'
还可以设置为绝对路径 ('' 或者 './'),这样所有的资源都会被链接为相对路径
css.loaderOptions 属性
向 CSS 相关的 loader 传递选项
Ant-design-vue 的样式变量:https:lww,antd,com docs/vue/customize-theme-cn
https://github.com/vueComponent/ant-design-vue/blob/master/components/style/themes/default.less
添加更多的 CSS 预处理器:
https://cli.vuejs.org/zh/guide/css.html# 预处理器
特别注意 less 和 Iess-loader 的版本问题。不要装最新的,建议选用:
//vue.config.js 配置: | |
const isstaging = !process.env.VUE_APP_STAGINE | |
const isProduction = process.env.NODE_ENV 'production' | |
module.exports = { | |
/生产环境要使用0SS地址 | |
/其他环境都使用绝对路径 | |
publicPath:(isProduction 6 !isStaging)'https://oss.imooc-lego.com/ | |
css:{ | |
loaderOptions:{ | |
less:{ | |
lessoptions:{ | |
modifyVars:{ | |
'primary-color':'#3E7FFF', | |
}, | |
javascriptEnabled:true | |
} | |
}, | |
configureWebpack: config => { | |
config.plugins.push( | |
new webpack.IgnorePlugin({ // 打包时忽略对应的文件 | |
resourceRegExp: /^\.\/locale$/, | |
contextRegExp: /moment$/, | |
}) | |
) | |
if(isAnalyzeMode){ | |
config.plugins.push( | |
new BundleAnalyzerPlugin({ // 添加打包后的文件分析工具(BundleAnalyzerPlugin) | |
analyzerMode : 'static', | |
}) | |
) | |
} | |
} | |
} |
# 项目构建优化
好用的 webpack 插件:webpack-bundle-analyzer
可视化 webpack 打包后的工具包大小,便于分析依赖和进行项目优化。如上 vue.config.js 中配置。
根据图表的优化步骤
一、看看有没有什么重复的模块,或者没有用的模块被打包到了最终的代码中
二、看看 package.json, 对比一下是否有应该在 devDeps 的模块,被错误的放置到了 deps 当中
三、检查是否有重复加载的模块,或者是功能大体相同的模块。
比如:使用 es 版本的第三方库,享受 tree-shaking 的红利。
四、检查是否有没有用的模块是否打包到了最终的文件中,通过如下插件忽略对应的文件,从而 tree-shaking 掉忽略的文件(如国际化需要的各种语言包), 详细配置如上 vue.config.js 中。
webpack ignore plugin: https://webpack.js.orglplugins/ignore-plugin/#root
将三方库中全部导入更换为按需导入
import {Input,Dropdown,Slider,Select} from 'Antd-vue'; | |
const components = [Input,Dropdown,Slider,Select]; | |
const install = (app) => { | |
components.forEach(item=>{ | |
app.component(item.name,item); | |
}) | |
} | |
export default{ install }; | |
// 在 main.js 中导入,然后 app.use |
浏览器缓存优化
一、项目即使是上线之后也会在后续追加或修改代码,如果分包较少重新上线后就不能使用浏览器缓存的文件,当分包数量较多时,就可以充分利用浏览器缓存。
二、分包较多时可以使用浏览器支持平行加载多个文件的特性。(HTTP1 对同一域名并行请求的个数进行了限制,HTTP2 完全突破了这个限制)
手动分割第三方库为多个文件
webpack 的 config.optimization 中自带一些优化的配置项:
- minimize:压缩
- splitChunks:分包(可以配置 minSize 等)
- 等等
//vue.config.js 配置: | |
module.exports = { | |
//.... 省略 | |
configureWebpack: config => { | |
config.optimization.splitChunks = { | |
maxInitialRequests: Infinity, | |
minSize: 300 * 1024, | |
chunks: 'all', | |
cacheGroups: { | |
antVendor: { | |
name: 'ant-design-vue', | |
test: /[\\/]node_modules[\\/](ant-design-vue)[\\/]/, | |
}, | |
canvasVendor: { | |
name: 'html2canvas, | |
test: /[\\/]node_modules[\\/](html2canvas)[\\/]/, | |
}, | |
vendor: { | |
name: 'vendor', | |
test: /[\\/]node_modules[\\/](!html2canvas)(!ant-design-vue)[\\/]/ | |
}, | |
all { | |
test: /[\\/]node_modules[\\/]/, // 匹配全部的 node_modules 中的文件 | |
name (module) { const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/) | |
return `npm.${packageName.replace('@','')}` | |
}, | |
} | |
} | |
} | |
} |
# 项目运行优化
路由懒加载
使用 import 函数动态加载,配合魔法注释可以和 webpack 中的 bundler 相配合使用,例如:
import(/* webpackChunkName: "my-lodash" */ 'lodash').then(lodash=>{ | |
// .... | |
}) |
改变 HTML 标题,增强 SEO
项目中动态添加标题的原理:使用 HtmlWebpackPlugin 插件,插入动态 js 语句进行占位,然后通过项目中 package.json 中的 name 进行替换。
//vue.config.js 配置: | |
module.exports = { | |
//.... 省略 | |
chainWebpack: config => { | |
config.plugin('html').tap(args=>{ | |
args[0].title = '网站标题', | |
args[0].desc = '网站详情描述' | |
return args; | |
}) | |
} | |
} | |
// 记得添加 <meta name="viewport" content="<%= htmlWebpackPlugin.options.desc %>"> |
同构渲染方式
服务端渲染和客户端渲染的区别就在于在哪里完成 html 完整文件的拼接:
# 客户端渲染
客户端渲染由客户端完成 html 文件的拼接,服务端只负责提供数据。
- 优势:首屏加载快
- 劣势:不利于 SEO
# 服务端渲染
服务端渲染由服务端完成 html 文件的凭借,客户端直接渲染即可
- 优势:利于 SEO,
- 劣势:白屏问题(获取 html 文件较慢),服务端压力大,占用 CPU 资源。
# 同构渲染
服务端先通过服务端渲染,生成 html 以及初始化数据,客户端拿到代码和初始化数据,在客户端进行激活渲染。
- 优势:兼容了前端渲染的大部分优点(节省服务端资源、多终端适配渲染、局部刷新等),同时也具有服务端渲染首屏加载快,SEO 支持好的特点。
- 劣势:服务端必须是要 js 支持的语言,增加了整个系统的复杂度和维护成本。
# SSG 预渲染
静态站点生成 (Static-Site Generation,缩写为 SSG),也被称为预渲染,是另一种流行的构建快速网站的技术。
如果用服务端渲染一个页面所需的数据对每个用户来说都是相同的,那就可以只渲染一次,提前在构建过程中完成,而不是每次请求进来都重新渲染页面。预渲染的页面生成后作为静态 HTML 文件被服务器托管。
SSG 保留了和 SSR 应用相同的性能表现:它带来了优秀的首屏加载性能。同时,它比 SSR 应用的花销更小,也更容易部署,因为它输出的是静态 HTML 和资源文件。这里的关键词是静态:SSG 仅可以用于消费静态数据的页面,即数据在构建期间就是已知的,并且在多次部署期间不会改变。每当数据变化时,都需要重新部署。
如果你调研 SSR 只是为了优化为数不多的营销页面的 SEO (例如 /、/about 和 /contact 等),那么你可能需要 SSG 而不是 SSR。SSG 也非常适合构建基于内容的网站,比如文档站点或者博客。VitePress 就是一个由 Vite 和 Vue 驱动的静态站点生成器。
Vite 脚手架渲染 SSG 代码示例。
# 部署与 HTTP 优化
# 部署
前端部署:https:llci,uejs,org/zh/guide/deployment.html
原理就是:将构建生成的产物直接烤贝到任何的静态文件服务器当中。
后端部署:https:/eggis.org/zh-cn/core/deployment.html
几乎没有构建过程:除非你用了 typescript 等需要编译的语言。
方案一:直接将本地的源代码打个压缩包拷贝到目标服务器,然后启动服务器。
方案二:在服务器中直接 pu 川源代码,install,. 然后启动服务器。
# Nginx: 反向代理
Nginx 作为服务器软件,它的优点:
- 特别适合前后端分离的项目
- 保证安全
- 非常快
- 支持负载均衡
使用:
- 安装 nginx
- nginx 命令启动服务器
- nginx -s stop 命令关闭服务器
- nginx -v 命令查看配置信息
- nginx -s reload 命令重启服务
- 配置 nginx.conf 文件
# HTTP 缓存
(若服务器使用 nginx,则在 nginx.conf 中配置)
Expires https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Expires
Expires 响应头包含日期 / 时间,即在此时候之后,响应过期
使用 nginx 添加对应的响应头:expires 指令
文档地址:http:l/nginx.org/en/docs/http/ngx http headers module.html
但是由于客户端时间和用户端时间并不总是相同的,于是有了 Cache-Control:
Cache-Control: 通用消息头字段,被用于在 http 请求和响应中,通过指定指令来实现缓存机制。
文档地址:https://developer mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control
*Etag:ETagHTTP 响应头是资源的特定版本的标识符。这可以让缓存更高效,并节省带宽
因为如果内容没有改变,Wb 服务器不需要发送完整的响应,直接返回 304 表示可以使用缓存文件。
* 文档地址:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/ETag
Last-Modified: 是一个响应首部,其中包含源头服务器认定的资源做出修改的日期及时间。
文档地址:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Last-Modified
nginx Etag:http://nginx.org/en/docs/http/ngx_http_core_module.html#etag
304 Not Modified https://developer.mozilla.org/zh-CN/docs/Web/HITP/Status/304
浏览器使用缓存:
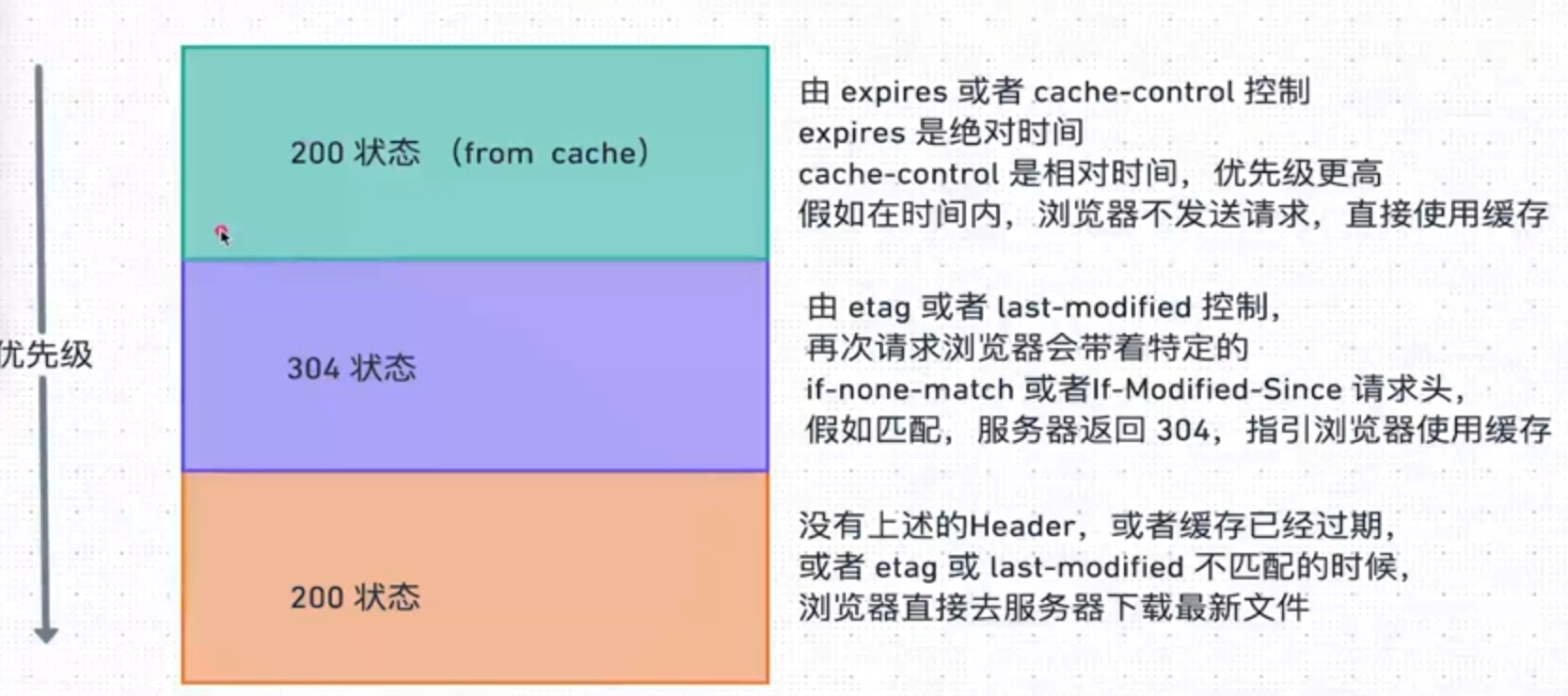
# 压缩算法
压缩比对照表
https://quixdb.github.io/squash-benchmark/#ratio-vs-compression
# gzip
一、动态压缩(服务器在返回静态文件之前,由服务器对每个请求压缩后再进行输出)
nginx 中启用 gzip:在 nginx.conf 中配置:
- gzip on; 开启 gzip
- gzip_types text/plain application/javascript 设置那些文件需要压缩
- gzip_min_length 1k; 小于设置值不会压缩
- gzip_comp_level 1; 压缩级别
- 等等
二、静态压缩(服务器直接使用压缩文件进行输出)
两个步骤
- 生成压缩文件(gzip 命令或使用 webpack 插件 compression-webpack-plugin)
- 在 ngin× 开启支持静态压缩的模块(例如 gzip_static : on)
# Brotli
一、动态压缩(服务器在返回静态文件之前,由服务器对每个请求压缩后再进行输出)
使用前提
浏览器支持:https:caniuse.com/brotli
HTTPS 协议
NGINX 对应的模块:https:/github.com/google/nginx/brotli
nginx 中启用 Brotli:在 nginx.conf 中配置:
- brotli on; 开启 Brotli
- brotli_types text/plain application/javascript 设置那些文件需要压缩
- 等等
二、静态压缩(服务器直接使用压缩文件进行输出,如上。)
# HTTP 优化
HTTP 是建立在 TCP 协议之上,所以 HTTP 协议的瓶颈及其优化技巧都是基于 TCP 协议本身的特性,例如 tcp 建立连接的 3 次握手和断开连接的 4 次挥手以及每次建立连接带来的延迟时间。所以减少这些重新握手和至关重要。
# keepAlive 属性
keepAlive 属性可以保持服务器端和客户端建立的会话连接,开启之后除首次建立连接外的其他请求不会进行 DNS Lookup(NDS 域名解析)和 Initial connection(三报文握手建立连接),可以在服务端文件中进行配置。
KeepAlive 的优点
- TCP 连接更少,这样就会节约 TCP 连接在建立、释放过程中,主机和路由器上的 CPU 和内存开销。
- 网络拥塞也减少了,拿到响应的延时也减少了
# HTTP2
使用 HTTP/2 提升性能
- 2010 年 SPDY https://baike.baidu.com/item/SPDY 演化到
- 2015 HTTP/2 https://developer.mozilla.org/zh-CN/docs/Glossary/HTTP_2
兼容性
需要浏览器支持 - https:/caniuse.com/http2
需要 HTTPS 协议支持
主要特性
- 二进制协议:
HTTP2 由原来的文本请求(报文)转变为二进制请求帧,加快传输
- 多路复用:
HTTP2 多路复用解决了浏览器同一域名并行请求数量的限制。
在 HTTP/2 中引入了多路复用的技术。多路复用很好的解决了浏览器限制同一个域名下的请求数量的问题,同时也接更容易实现全速传输,毕竟开一个 TCP 连接都需要慢慢提升传输速度。
同个域名只需要占用一个 TCP 连接,使用一个连接并行发送多个请求和响应,消除了因多个 TCP 连接而带来的延时和内存消耗。
- Header 压缩复用
TTP/2 在客户端和服务器端使用 “首部表” 来跟踪和存储之前发送的键一值对,对于相同的数据,不再通过每次请求和响应发送。
配置 HTTP2:
依 nginx 为例:在 server 字段的 listen 字段添加:listen 443 ssl http2;
# Mongodb 数据库
# 基本操作
// 导入 Mongodb 客户端构造函数 | |
import { MongoClient,ObjectId, } from "mongodb"; | |
// 创建 mongo 实例 (传入 url) | |
const client = new MongoClient('mongodb://localhost:27017/'); | |
// 执行函数,连接 mongodb 数据库 | |
async function run() { | |
try { | |
await client.connect(); // 等待实例连接 | |
const db = client.db('hello'); // 创建数据库 | |
const res = await db.command({ ping: 1 }); //ping 命令 | |
console.log('connected', res); | |
const userCollection = db.collection('user');// 创建集合表 | |
// 数据的插入 | |
//const result = await userCollection.insertOne ({name:"张三",age:18}) | |
//const results = await userCollection.insertMany ([{name:"李四",age:12},{name:"王五",age:13}]); | |
//console.log (result,results); // 返回影响的信息,id 等 | |
// 数据的查找 | |
const result = await userCollection.findOne({name:'张三'}); | |
console.log(result); | |
const resultCursor = userCollection.find(); //find 返回的是指针对象,不是结果 | |
// 将游标变为数组结果 | |
const results = await userCollection.find().toArray(); | |
// console.log(results); | |
// 比较操作符 $lt 小于 $gt 大于 | |
const results2 = await userCollection.find({age:{$lt:16}}).toArray(); | |
// console.log(results2); | |
// 逻辑操作符 $or | |
const results3 = await userCollection.find({$or:[{age:{$gt:12}},{name:"王五"}]}).toArray(); | |
// console.log(results3); | |
// 元素操作符 $exists 存在与否 $type 指定类型 | |
const results4 = await userCollection.find({age:{$type:'number'}}).toArray(); | |
// console.log(results4); | |
//limit 第二个参数传入 options 配置(projection 表示包含字段哪些字段) | |
const result5 = await userCollection.find({age:{$type:'number'}},{limit:2,skip:3,sort:{age:-1},projection:{name:0}}).toArray(); | |
// console.log(result5); | |
// 更新替换数据 update 更新数据 replaceOne 替换数据,修改操作要传具体更新操作符: | |
// 普通更新操作符: $set 设置值 $inc 增加 $rename 重命名 $unset 删除 | |
// 数组更新操作符: $push 数组字段添加 $pop 删除 $all 包含 $regex 正则。属性符 .$ 属性占位符 | |
const result6 = await userCollection.replaceOne({name:"张三"},{name:"Lebrown"}); | |
const result7 = await userCollection.updateOne({_id:new ObjectId('6628b9876bac632e95ead1bb')},{$set:{name:"updateOne"},$inc:{age:10}}); | |
const result8 = await userCollection.updateOne({_id: new ObjectId('6628b9876bac632e95ead1bb')},{$set:{"hobbies.0":"golf"}}) | |
const result9 = await userCollection.updateOne({_id: new ObjectId('6628b9876bac632e95ead1bb'),hobbies:'glof'},{$set:{"hobbies.$":"golf-new"}}) | |
//console.log (result8);// 返回影响信息 | |
// 删除数据:deleteOne (filter) 和 deleteMany | |
} catch (e) { | |
console.error(e); | |
} finally { | |
await client.close(); | |
} | |
} | |
run(); |
# mongodb 高级
# 索引
MongoDB 索引
- 索引 (Index) 为了提高查询效率
- MongoDB 的文件类型:BSON,Binary JSON, 主要被用作 MongoDB 数据库中的数据存储和网络传输格式。
- 假如没有索引,必须扫描这个巨大 BSON 对象集合中的每个文档并选取那些符合查询条件的记录,这样是低效的。
- 索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中。
- 为某个字段创建索引之后查找速度非常快,ObjectId 是自带的索引( _ id _ )。
创建索引
创建索引可以直接用 Navicate 等工具,也可以代码中使用:
//...... 省略 | |
// 给 name 字段创建索引之前耗时很大,创建之后耗时很小 | |
const indexResult = await userCollection.find({name:"James"}).explain(); | |
console.log(indexResult); | |
// 创建索引,属性表示字段,值表示升序降序 | |
const result = await userCollection.createIndex({name:1}) //1 表示升序 | |
// 取消索引 | |
const result1 = await userCollection.dropIndex("name_1") |
# 聚合
聚合操作将来自多个文档的值组合在一起,并且可以对分组数据执行各种操作以返回相应的结果。
linux 常用的管道写法:
ps aux | grep mongo |
聚合常用的操作符:
- $group 将 collection 中的 document: 分组,可用于统计结果
- $natch 过滤数据,只输出符合结果的文档
- $project 修改输入文档的结构(例如重命名,增加、删除字段,创建结算结果等)
- $sot 将结果进行排序后输出
- $imit 限制管道输出的结果个数
- $skp 跳过制定数量的结果,并且返回剩下的结果
表达式操作符:
- sum计算总和,{sum:1} 表示返回总和 ×1 的值(即总和的数量),使用 { 制定字段 '} 也能直接获取制定字段的值的总和
- $avg 求平均值
- $min 求 min 值
- $max 求 max 值
- $push 将结果文档中插入值到一个数组中
- $frst 根据文档的排序获取第一个文档数据
- $last 同理,获取最后一个数据
//..... | |
const pipeLine = [ | |
{ $match : { age : { $gt : 30 }}}, | |
{ $group : { _id : "$steam" , total : { $sum : "$age" } , count : { $sum : 1 }}}, | |
{ $sort : { total : 1 }} | |
] | |
cosnt result = await userCollection.aggregate(pipeLine).toArray(); | |
//.... |
# 多表联查
普通方式使用多表联查需要两次查询
// 导入 Mongodb 客户端构造函数 | |
import { MongoClient,ObjectId, } from "mongodb"; | |
// 创建 mongo 实例 (传入 url) | |
const client = new MongoClient('mongodb://localhost:27017/'); | |
// 执行函数,连接 mongodb 数据库 | |
async function run() { | |
try { | |
await client.connect(); // 等待实例连接 | |
const db = client.db('hello'); // 创建数据库 | |
const res = await db.command({ ping: 1 }); //ping 命令 | |
console.log('connected', res); | |
// 获取表 | |
const teamCollection = db.collection('team'); | |
const playerCollection = db.collection('player'); | |
const netsTeam = await teamCollection.findOne({team:"NETS"}); | |
const netsPlayers = await playerCollection.find({team:netsTeam._id}).toArray(); | |
} catch (e) { | |
console.error(e); | |
} finally { | |
await client.close(); | |
} | |
} | |
run(); |
使用聚合中 $lookup 进行多表联查只需要一次查询:
//... | |
const pipeLine2 = [ | |
{ | |
$match : { team : { $exists : true } } | |
}, | |
{ | |
$lookup : { | |
from : "team", | |
localField : "team", | |
foreignField : "_id", | |
as : "team" | |
} | |
} | |
] | |
const playerWithTeam = await playerCollection.aggregate(pipeLine2).toArray(); | |
console.log(playerWithTeam); | |
//... |
# 数据库设计
[MongoDB 最佳设计实践](https://www.mongodb.com/developer/article/mongodb-
schema-design-best-practices/)
关键问题:数据产生关系的时候,选择内嵌还是引用?
内嵌模式:
优势:
- 只需要一次查询就可以查询所有的信息。
- 避免多集合查询。
- 只需要一个操作就可以更新多个信息。
劣势:
- 单个文档太大,查询可能更耗时,获得的无关信息概率增大。
- 针对每个文档,MongoDB 有一个 16M 的最大限制,内嵌太多,可能超过这个限制。
引用模式:
优势:
- 将数据分散到不同文档,数据量会变小。
- 不太会超过 16M 最大限制。
- 每次查询取得不必要数据的慨率降低。
劣势:需要多次查询才能获得最终数据
最佳设计实践:
一对几个:推荐使用内嵌形式
一对很多:推荐使用引用形式
- 子集合中使用一个字段保存父集合的_id ; 或者:
- 父集合中使用一个数组保存子集合的_id
一对亿万:只能子集合中使用一个字段保存父集合的_id
# 访问权限管理
授权文档:https://docs.mongodb.com/manual/core/authentication/
内置的 Roles:https://docs.mongodb.com/manual/reference/built-in-roles/
在 mongo 命令行中输入:
show dbs
use admin
# mongodb基于RBAC进行权限管理,设置roles可以设置相应的全选,见上。
db.createUser({ user : 'root' , pwd : '123456' , roles : ['root'] })
db.auth('root','123456')
# --auth 开启数据库的权限验证,也可以直接在mongo.conf中配置(先终止运行mongod)
mongod --config /usr/local/etc/mongo.conf --auth
# 操作配置了权限管理的数据库
mongo -u "root" -p "123456" --authenticationDatabase "admin"
初始化一个新数据库以后期望的步骤
- 创建 admin 级谜别的 root 用户 /roles:root
- 创建对应的数据库 lego
- 创建该数据库的管理员 dmq/roles:readWrite
- 代码中,使用管理员 dmq 的用户名密码链接数据库并且完成操作。
步骤如下:
show dbs
use lego
db.createUser({ user : "dmq" , pwd : '123456' , roles : [{ role : "readWrite" , db : "lego" }]})
# 重启服务:mongod --config /usr/local/etc/mongo.conf --auth
# 这样在mongodb的配置文件中设置用户信息,就保证只能读取数据库信息,保证了数据库的安全。(如果用户信息来自admin数据库就需要配置authSource:'admin'。)
# Mongoose
出现的原因:
使用原生的 mongoDB nodejs driver 数据结构及其操作过于灵活。
mongoose:MongoDB 的 ODM 文档对象映射(mongoose 之于 mongodb 类似于 ts 之于 js,都是在原有的基础之上加一层抽象层,进行类型定义等操作)
mongoose:https://mongooseis.com/
- 建立在 native mongoDB nodejs driver 之上
- 提出 Modl, 数据模型的概念,用来约束集合中的数据结构
- 非常多扩展的内容
- 它是一个 ODM (Object Document Mapping) 工具。
# ORM
ORM 指的是 Object Relational Mapping 对象关系映射,针对于关系型数据库。
简单说,ORM 就是通过实例对象的语法,完成关系型数据库的操作的技术。
ORM 优点
- 不需要再去写晦涩的 SQL 语句。
- 使用面向对象的方式操作数据,代码量少,语义性好,容易理解。
- Classes 类 - Tables
- Objects 实例 - Records (表中的一行数据)
- Attributes 属性 - Records
- 内置很多功能,数据验证,清洗,预处理等等操作。
# ODM
ODM 指的是 Object Document Mapping 对象文档映射。ODM 针对于 noSql 数据库,关注文档模型,mongoose 是 ODM 的一种实现,可以用于约束数据类型。
const User = mongoose.model("User",{ | |
username:{ type : string }, | |
password:{ type : String } | |
}) | |
//user object | |
const newUser new User({ | |
username:"john-doe", | |
password:"helloworld", | |
}) | |
await newUser.save() |
# egg-mongoose
官网文档很好,请自行查看。
# Stream
# 介绍
Stream 的官方文档:https://nodejs.org/api/stream.html
流是 Node.js 中最好,也是最容易误解的慨念
流就是数据的合集,数据可以是字符串也可以是数组,流的数据不是一次性全部获得的。
大文件输出方式:
直接读取
输入的文件 ------------ 读取到内存 ---------------- 输出文件内容
流式读取
输入的文件 ------------ 通过可读流读取到管道 ----------------- 通过可写流输出文件内容
Node.js 支持流的内置模块:
Readable Streams:
- HTTP responses,on the client
- HTTP requests,on the server
- fs read streams
- zlib streams
- crypto streams
- TCP sockets
- child process stdout and stderr
- process.stdin
Writable Streams:
- HTTP requests,on the client
- HTTP responses,on the server
- fs write streams
- zlib streams
- crypto streams
- TCP sockets
- child process stdin
- process.stdout,process.stderr
流的类型:
- Readable - 可读操作。
- Vritable - 可写操作。
- Duplex - 可读可写操作.
- Transform - 操作被写入数据,然后读出结果。
# pipe
流的流动:
可读流 Readable(数据源 input)----------------------pipe 管道 ---------------------------------------- 可写流 Writable(输出 output)
import { createReadStream, createWriteStream } from 'fs'; | |
const readStream = createReadStream('./a.txt'); | |
readStream.pipe(process.stdout); |
可读流 Readable(数据源 input)-------------pipe 管道 --------------- 转换流 Transform----------------pipe 管道 ----------- 可写流 Writable(输出 output)
import { createReadStream, createWriteStream, write } from 'fs'; | |
const readStream = createReadStream('./a.txt'); | |
const writeStream = createWriteStream('./b.txt'); | |
readStream.pipe(writeStream); |
# 原理
流是基于 EventEmitter(事件),pipe 方法是基于事件封装的的语法糖,常见的事件有:
Readable Streams:可读流事件和函数
- Events
- data-- 当没有数据时触发
- end-- 没有更多的数据可读时触发
- error-- 在接受和写入过程中发生错误时触发
- finish-- 所有数据已被写入到底层系统时触发
- close
- readable
- Functions
- pipe() , unpipe()
- read() , unshift() , resume()
- pause() , isPaused()
- setEncoding()
Writable Streams:写入流事件和函数
- Events
- drain
- finish
- error
- close
- pipe/unpipe
- Functions
- write()
- end()
- cork() , uncork()
- setDefaultEncoding()
pipe 方法原理:
import { createReadStream , createWriteStream } from 'fs'; | |
const readStream = createReadStream('./a.txt'); | |
const writeStream = createWriteStream('./b.txt'); | |
readStream.on('data' , chunk=>{ | |
writeStream.write(chunk); | |
}) | |
readStream.on('end',()=>{ | |
writeStream.end(); | |
}) |
压缩:
import { createReadStream , createWriteStream } from 'fs'; | |
import { createGzip } from 'zlib'; | |
const readStream = createReadStream('./a.txt'); | |
const writeStream = createWriteStream('./b.txt'); | |
readStream.pipe(createGzip()).pipe(writeStream); |
封装:
cosnt savePromise = (readStream , writeStream = stdout){ | |
return new Promise(resolve,reject){ | |
readStream | |
.pipe(writeStream) | |
.on('finish',resolve) | |
.on('error',reject) | |
} | |
} |
# pipeline
使用 pipe 方法有时会存在一个问题:
//.... | |
createReadStream('./a.txt') | |
.pipe(stdout) | |
.on('finish',finishFn) | |
.on('error',errFn); // 这里监听的是 pipe 后的错误,对于 createReadStream 的错误则会卡死 |
于是推出了 pipeline 方法:
//... | |
pipeLine(fs.createReadStream('./a.txt'),zlib.createGzip(),fs.createWriteStream('./b.txt'),(err)=>{ | |
if (err) { console.error('pipeline failed',error) }; | |
else { console.log('successed') } | |
}) |
# 对象存储服务
自己完成静态文件存储的问题
- Nod.js 不擅长处理静态文件的存储和展示,没有未静态文件做特殊的优化
- 如果将图片生成多种处理格式要耗费大量的资源和空间
各三方比对
# 阿里云 OSS
特点
- 支持丰富的图片处理 https://help.aliyun.com/document._detail/44686.html
- egg.js 有对应的插件:https://github.com/eggjs/egg-oss
价格
- 下行流量 100GB 一年 352 元 https://common-buy.aliyun.com/?spm=5176.7933691.J_5253785160.1.2e394c59q3FIsA&commodityCode=ossbag#/buy
- 基本图片处理:每月 0-10TB: 免费 > 10TB:0.025 元 / GB
# 七牛云 KODO
特点:
- 多媒体处理功能非常丰富 https://www.giniu.com/products/dora
- 图片视频处理
- 审核
- 人工智能分析
价格:
- 外网流出 100GB - 年 278.4 元 https://qmall.qiniu.com/template./MTEy?spec_combo=MzE0NQ
- 基本图片处理:每月 0-20TB: 免费 20TB 以上:0.025 元 / GB https:/www.qiniu.com/prices/dora
# 腾讯云 COS
特点:
图像处理有一些新的亮点,比如自研的 TPG 压缩等
价格:
- 外网流出 100GB 一年 396 元 https://buy.cloud.tencent..com/price/cos#tab0-list1
- 基本图片处理:每月 0-20TB: 免费 20TB 以上:0.025 元 / GB
- https://cloud.tencent.com/document/product/1246/45274
- 图片压缩:1 元 / 千次
# SSR 服务端渲染
# 介绍
SSR-Server Side Rendering
Vue 关于 SSR 的介绍:https://sSr.uejs.org/zh
SSR 的优点
- 更好的 SEO
- 更快的渲染时间 (Time to content),
SSR 的缺点
开发的限制,浏览器相关的操作只能在特定的钩子函数中使用
SPA 应用完全静态化,而 SSR app 需要 Node.js Server 才能运行
服务端负荷更高
SSR 的实现:
基本原理:@vue/server-renderer https://v3.uejs.org/guide/ssr/getting-started.html#installation
使用 createSSRApp,renderToString 以及 renderToStream 方法
成熟的,大而全的 SSR 通用开发框架:
- Nuxt.js https://nuxtjs.org/ (Vue)
- React 类似的 Next.js https://nextjs.org (React)
# SSR
express 等框架的 res.render 方法可以渲染 html 模板,使用的是 nunjucks 库进行数据填充。
index.html
<!DOCTYPE html> | |
<html class="no-js"> | |
<head> | |
<meta charset="UTF-8"> | |
<meta name="description" content=""> | |
<meta name="viewport" content="width=device-width, initial-scale=1.0"> | |
<title>Document</title> | |
</head> | |
<body style=""> //根据传入的props动态添加style样式 | |
</body> | |
</html> |
index.js (依据 express 框架为例:)
//...res 是响应参数 | |
res.render('index',function(err,html){ | |
res.send(html); | |
}) |
# vue 中 SSR
1、vue3 有包:@vue/server-renderer,在 3.2.13 版本以上内置了,低于此版本需要自行安装。
2、使用:
//.......... res 是服务端返回 | |
import { pipeline } from 'stream/promises'; | |
import { createSSRApp } from 'vue'; | |
import { renderToString , renderToNodeStream } from '@vue/server-renderer' | |
const vueApp = createSSRApp({ | |
data:()=>{ msg:'hello world' }, | |
template: '<h1></h1>' | |
}) | |
const appContent = await renderToString(vueApp); | |
res.type = 'text/html'; | |
res.body = appContent; | |
// 或者使用流式输出: | |
const stream = renderToNodeStream(vueApp); | |
res.statys = 200; | |
await pipeline(stream,res); |
# RBAC 权限验证
# 介绍
权限验证的场景以及需求:
- 特定的角色的用户才能操作特定的资源
- 不同的用户能操作同类资源的特定实体
- 不同的用户操作特定资源的不同属性
谁 (User) 拥有什么权限 (Authority)去操作 (Operation) 哪些资源 (Resource)
根据角色完成权限的控制 - RBAC (role based access control),其实就是在原本用户 ------- 权限的对应关系之上加一层中间层角色:用户 ------ 角色 ----- 权限。好处是使得用户和权限的对应关系更加清晰和易于掌控。
# 使用
Node.js 实现 RBAC 的库:
AccessControl.js(不推荐,不维护了)
- 1.6k Star
- 3 年没有更新,很多 issue 没人处理
- 不支持 ts
Casbin
- 1.7k Star
- ts 编写,支持多种编程语言
- 概念比较复杂,使用略繁琐
Casl
3.4k Star
ts 编写
简单易用,可读性良好
# Casl 使用
import { AbilityBuilder , Ability } from '@casl/ability'; | |
class Work { | |
constructor(attrs){ | |
Object.assign(this,attrs); | |
} | |
} | |
const templateWork = new Work({ id : 1 , isTemplate : true }); | |
const notWork = new Work({ id : 2 , isTemplate : false }); | |
function defineRules(){ | |
const { can , cannot ,build } = new AbilityBuilder(Ability); | |
can('read','Work'); | |
cannot('delete','Work'); | |
can('update','Work',{isTemplate:false}); | |
return build(); | |
} | |
console.log(templateWork.constructor.name) | |
const rules defineRules() | |
console.log(rules.can('read','Work')) | |
console.log(rules.can('delete','Work')) | |
console.log(rules.can('update',templateWork)) | |
console.log(rules.can('update',notWork)) |
# 部署
# 传统模式
本地开发
使用 egg-bin,提供了便捷的方式在本地进行开发、调试、单元测试,它可以自动的监控文件的修改,然后重新运行对应的命令。
采用的配置文件是:config.default.ts
启动开发环境命令为 egg-bin dev
生产环境运行程序
pm2-process manager
node script.js | |
pm2 start script.js |
PM2 的优势:
- cluster(集群)模式运行
- 自动重启 auto reload
- 热替换 hot reload
- 性能监控 Monitoring
egg.js 中有对应于 PM2 的内置方法:
- egg-scripts
- egg-cluster
egg.js 生产环境启动和关闭
egg-scripts start
egg-scripts stop
配置文件
config.prod.ts 和 config.default.ts
编译过程
需要手动将 ts 转换为 js, 借助 ets特别注意将项目中的typscript版本升级到4.4.3
npm run tsc |
# Cluster 模型
Egg.js Cluster 模型的原理
Egg.js 关于这部分内容的文档:https://eggjs.org/zh-cn/core/cluster-and-ipc.html
为什么要采用 Cluster 模式
JavaScript 代码是运行在单线程上的,那么如果用 Node.js 来做 Web Server, 就无法享受到多核运算的好处。
什么是 Cluster 模式
文档:http://nodejs.cn/api/cluster.html
Node.js 的单个实例在单个线程中运行。为了利用多核系统,用户有时会想
要启动 Node.js 进程的集群来处理负载。
- 在服务器上同时启动多个进程
- 每个进程里都跑的是同一份源代码(将一个进程的工作分给多个进程去做)
- 这些进程可以同时监听一个端口
Cluster 的运行模式:
Request-------------master_process 主进程 ---------------------workers 进程(多个)
进程间通信(IPC):
IPC Inter-Process Communication
IPC 指的是至少两个进程或线程间传送数据或信号的一些技术或者方法,Node.js 将其封装为基于事件的形式便于使用。
Cluster 使用:
import http from 'http'; | |
import cluster from 'cluster'; | |
import { cpus } from 'os'; | |
import process from 'process'; | |
if(cluster.isPrimary){ // 通过 cluster.isPrimary 来分支处理主进程和 worker 进程 | |
console.log(`master ${process.pid} running`); | |
const cpuLength = cpus().length; | |
for(let i = 0 ; i < cpuLength ; i++){ | |
cluster.fork(); | |
} | |
cluster.on('exit',(worker)=>{ | |
console.log(`worker ${worker.process.pid} exited`); | |
}) | |
}else{ // 分支判断到是 worker 进程,cluster.fork () 复制的 worker 进程都会进入 | |
http.createServer((req,res)=>{ | |
res.writeHead(200); | |
res.end("hello world"); | |
}).listen(8000); | |
console.log(`worker ${ process.pid } started`); | |
console.log(cluster.workers); // 获得子进程,可以通过 process.send 和 on ('message') 事件进行进程间通信。 | |
} |
egg.js 中对于 Cluster 的二次封装:
- 使用 egg-scripts 启动 master process
- 使用 egg-cluster 启动和 CPU 核数相等的 app_worker process
- 使用 egg-cluster 启动的一个独特的 agent_worker process
进程守护
考虑到生产环境的健壮性,必须保证进程异常的情况下怎样处理。
当代码抛出异常并没有被捕获的时候,worker 使用 process.on ('uncaughtException',handler) 来捕获对应的错误,这时进程处于不确定的状态,需要优雅退出。
系统异常
而当一个进程出现异常导致 crash 或者被系统杀死时,不像未捕获异常发生时我们还有机会让进程继续执行,Master 立刻 fork 一个新的 Worker。
Agent 机制
有一些特殊性质的工作,不能多个 worker 一起合作,容易造成混乱。对于这种工作 egg.js 提供了一个新的 agent 进程来完成。
Egg.js 三种进程的总结:
| 类型 | 进程数量 | 作用 | 稳定性 | 是否运行业务代码 |
|---|---|---|---|---|
| Master 进程 | 1 | 进程管理,进程间消息转发 | 非常高 | 否 |
| Agent 进程 | 1 | 后台运行工作 | 高 | 少量 |
| Workers 进程 | CPU 核数 | 执行业务代码 | 一般 | 是 |
Cluster 模型和 Node 多进程的区别:
- Cluster 模块可以将一个 node 进程分裂成多个子进程,每个子进程独立运行在 cpu 内核上,以提升应用程序的并发能力和性能,通过主进程和子进程之间的通信来实现负载均衡,处理并发请求。
- node 多进程使用 child_process 模块,其不具备负载均衡和通信机制,需要自行实现进程间通信和负载均衡逻辑。可用于处理长时操作,返回结果给主进程。
Node.js 压力测试工具:
模拟高并发场景:Loadtest
# n 总过发送多少个请求 | |
# c concurrency 同时有几个客户端在发送请求 | |
# rps request per seconds 每秒发送多少个请求 | |
loadtest -n 400 -c 10 --rps 200 http://mysite.com/ |
# 云服务器
# 购买
阿里云 ECS
腾讯云 CVM
价格(学生优惠):https://cloud.tencent.com/act/campus?from=14599 12G 38
华为云 ECS
# 登录
为什么使用 root 登录时一个不好的实践
- 有非常多的 bot 会尝试使用 root+pwd 的 ssh 方式暴力登录机器,当尝试成功以后,黑客就会控制整个系统。
- 假如使用特定用户名 + pwd,bot 需要先猜测用户名 (N 次),然后是密码 (M 次),这样复杂度提升到 N*M
- root 可以造成更大的危害,影响整个系统,而某个特定用户只能影响它的文件系统
创建一个用户账号进行登录
# 远程登录 | |
ssh root@xxx.xx.xx.xx | |
# 添加用户以及设置密码 | |
adduser dmq |
设置该用户拥有 sudo 权限,给予它在登录以后切换到 root 的能力
# 修改权限,u 表示所有者,w 表示写权限 + 表示添加 | |
chmod u+w /etc/sudoers | |
# 编辑文件 | |
vim /etc/sudoers | |
# 找到 `root ALL=(ALL) ALL` | |
# 再加一行 `dmq ALL=(ALL) ALL` |
使用新用户登录并且测试权限
ssh dmq@xxx.xx.xx.xx | |
# 可以使用 su 直接切换为 root 用户 | |
# 也可以使用 sudo 快捷的使用 root 权限进行操作 |
禁止使用 root 远程登录 ssh
# 修改 ssh 配置 | |
vim /etc/ssh/sshd_config I | |
# 修改 yes 为 no | |
PermitRootLogin no | |
# 重启 sshd 服务 | |
service sshd restart |
可选:不使用密码登录
为什么使用密码登录有时候是一个不好的实践?
非常简单:用户经常使用非常错误(简单的)用户密码,全球最常用的密码是 123456 以及 bc123, 而且用户会在多个账户大量重复使用,所以黑客从别的地方盗取的密码很可能在其他账户也可以使用
使用 SSH kev 进行登录
SSH key 采角了经典的非对称加密技术,可以使用工具创建一个公钥和私钥,你可以将公钥放置在任何的服务器当中,在本地保留私钥。在 ssh 登录的时候,SSH 验证公钥和私钥的合法性,当合法的时候,就可以免密码登录了。证书由 1024Bits 到 4096Bits(128 到 512 字符) 的随机字符组成,要比你自己的密码安全的多。
#创建 ssh key pair | |
ssh-keygen -t rsa -b 4096 -C "your email@example.com" | |
windows可以使用putty或者git scma软件生成,备注网址: | |
https://www.jianshu.com/p/95262f5eba7a | |
# 本地 ssh 证书的位置 | |
-/.ssh/id rsa | |
-/.ssh/id rsa.pub | |
# 登录远程机器 | |
ssh viking@xxx.xx.xx.xx | |
# 创建受信任的登录密钥 | |
# 这个文件当中的公钥会被当前的主机设置为信任方 | |
touch -/.ssh/authorized keys | |
# 将 id rsa.pub 的文本内容黏贴进来 |
可选,关闭密码登录服务器的功能
vim /etc/ssh/sshd config | |
#修改为 no | |
PasswordAuthentication no | |
#重启服务 | |
service sshd i restart |
# 使用
准备云服务器必备软件
- nodejs (16)
- MongoDB
- Redis
- Git
Linux 发行版的两大家族
- Debian (完全免费的 Linux 发行版)-Ubuntu (基于 Debian, 更加容易上手)-apt 包管理系统 - 软件格式为 deb 包大
- Red Hat (商用 Linux 发行版)-CentOS (Red Hat 减去收费软件)-yum 包管理系统 - 软件格式为 rpm
软件安装
安装 Node.js
1 安装 nvm 管理 node 版本 https://github.com/nvm-sh/nvm
2 使用包管理器安装 node 最新版本 https://github.com/nodesource/distributions/blob/master/README.md#deb
安装 MongoDB
1 从源代码下载安装,回顾之前的内容
2 使用包管理器安装
Ubuntu:https://docs.mongodb.com/manual/tutorial/install-mongodb-on-ubuntu/
Centos:https://docs.mongodb.com/manual/tutorial/install-mongodb-on-red-hat/
安装 Redis
1 从源代码下载安装,回顾之前的基础知识
2 使用包管理器安装
CentOS:https://www.digitalocean.com/community/tutorials/how-to-install-secure-redis-centos-7
Ubuntu:https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-redis-on-ubuntu-18-04
# 管理
使用 service 或者 systemctl 管理服务
# systemd 模块 - https://en.wikipedia.org/wiki/Systemd | |
service 服务名称(mongod) 操作指令(status/start/stop/restart) | |
systemctl 操作指令(start/stop/status/restart/reload) 服务名称service |
# 普通部署
在服务器上部署并运行
登录远程机器,使用普通用户。
在自己的目录下面,clone 代码
安装对应的依赖
可以使用 sharp 淘宝 mirror 来安装比较大的二进制文件。
https://sharp.pixelplumbing.com/install#chinese-mirror
创建并且设置.env 文件
开启云服务对应的端口 (7001) 访问。
阿里云:左侧导航 “本实例安全组”,“配置规则”,“手动添加 " 端口
其他云平台请自行查看。
启动服务器
确认 mongo,redis 在运行状态
npm run tsc
npm run start
于此可以完成基本的项目部署,但是这种部署方式启动和更新时过于复杂,存在如下问题:
三个问题
- 前置软件的安装,它们在不同操作系统中安装的方式,启动的脚本,预设初始的方式有可能都不相同,这就给我们造成一个很大的困扰,假如你在多台机器上部署的话,可能会遇到各种各样的问题。
- 项目需要运行一系列对应的命令才能启动
- 项目更新的问题,需要一系列手动的步骤,这是一个非常繁琐,而且容易出错的步骤。有没有更方便的方式可以完成这个过程呢?
- 完成对应的 pull 代码,更新依赖,启动应用的过程
- 是在特定的提交自动触发这个过程
想要更加方便的进行部署可以使用如下工具:
# Docker
# 介绍
问题
我们希望有一个工具可以帮我们一键智能部署,假如你要部署在多台不同的机器上,可以不用在担心不同系统,不同版本的差异,以及运行之前需要安装不同软件的痛苦。
解决
当红的虚拟化软件:Docker
Docker 的进化
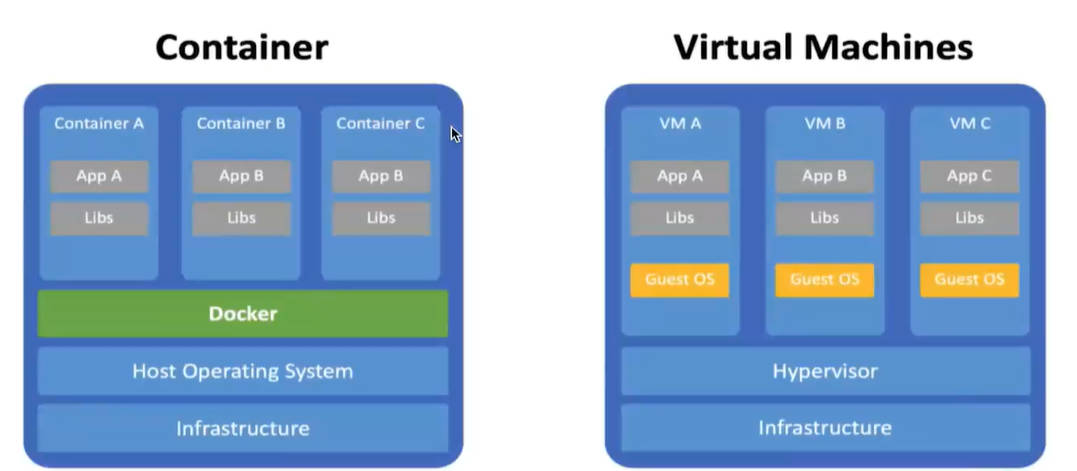
- 传统虚拟机,虚拟硬件以后,需要在上面安装一个完整的操作系统。
- Docker: 推出了容器的概念,每个容器不需要安装完成的操作系统,里面的进程直接运行在 Docker 创造的宿主内核中,不需要虚拟硬件。
Docker 的优点
- 更快速的启动速度
- 更少的资源占用
- 一致的运行环境,使用户不关注操作系统而只关心应用程序。
- 微服务架构,docker 天生适配微服务架构(Docker 有助于将一个复杂系统分解成一系列可组合的部分,这让用户可以用更离散的方式来思考其服务。用户可以在不影响全局的前提下重组软件,使其各部分更易于管理和可插拔。)
- 用户可以更准确地控制构建环境的状态,Docker 构建比传统软件构建方法更具有可重现性和可复制性。使持续交付的实现变得更容易。
# Docker images
可以在 https://hub.docker.com/search?g=&type=image 中获取各种官方的镜像,并且可以上传你自己的自定义镜像
Docker 镜像仓库获取镜像的命令是 docker pull
# 下载镜像 | |
docker pull <image-name>:<tag> | |
# 查看以及下载的镜像 | |
docker images | |
# 删除镜像 | |
docker rmi <image-id> | |
# 上传 | |
docker push <username>/<repository>:<tag> |
使用镜像代理:
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn/",
"https://reg-mirror.qiniu.com"
]
# Docker Container
启动 Docker 容器
docker run -d -p 主机端口:镜像端口 --name 容器名称 镜像名称 | |
# 例如:(--name 容器名称省略) | |
docker run -d -p 81:80 nginx | |
# -d 后台运行 | |
# -p 端口映射,81 为主机的端口,80 为镜像端口 | |
# --name 自定义容器名称 | |
# 镜像名称,假如本地没有,会自动 pull 一次镜像进行下载。 |
其他命令
# 查看所有容器 | |
docker ps | |
# 停止容器 | |
docker stop container-id | |
# 删除容器 | |
docker rm container-id | |
# 启动已终止容器 | |
docker container start container-id |
进入容器内部
docker exec -it <container-id> command | |
-i : 即使没有附加也保持STDIN 打开 | |
-t : 分配一个伪终端 |
# 持久化容器数据
使用 - v 参数,可以设定一个数据的映射关系,将本地的文件映射到容器中对应的文件中去。
docker run -d -p 81:80 -v host:container image-name | |
#例如:将本地数据卷映射到容器中 | |
docker run -d -v /data/db:/data/db mongo |
创建对应的数据卷 volumn
# 创建数据卷 | |
docker volume create <volumn-name> | |
#例如:docker volume create mongo | |
# 使用 volumn 数据卷 | |
docker run -d -v <volumn-name>:/data/db mongo | |
# 例如:docker run -d -v mongo:/data/db mongo | |
# 检查数据卷 | |
docker volume inspect <volumn-name> | |
# 删除数据卷 | |
docker volume remove mongo |
# Dockerfile 自定义镜像
Docker image 中的镜像虽然非常多,但是不能完全符合自己项目的全部需求,可以自定义构建一个自己的镜像。
Dockerfile 是一个特殊的文本文件,其中包括一系列指令,用于构建对应的镜像。
指令
Dockerfile 示例:
# 指定基础镜像,从 node14 开始构建 | |
FROM node:14 | |
# 创建对应的文件夹,作为项目运行的位置 | |
RUN mkdir -p /usr/src/app | |
# 指定工作区,后面的运行任何命令都是在这个工作区中完成的 | |
WORKDIR /usr/sec/app | |
# 从本地拷贝对应的文件 到 工作区 | |
COPY server.js /usr/src/app | |
# 执行安装命令 | |
RUN npm install --registry=https://registry.npm.taobao.org | |
RUN npm run tsc | |
#告知当前 Docker image 暴露的是 3000 端☐ | |
EXPOSE 3000 | |
#执行启动命令,一个 Dockerfile 只能有一个 | |
CMD node server.js |
构建:
# 这里特别注意上下文的概念,不要在根目录使用 Dockerfi1e | |
docker build [选项] <上下文路径/URL/-> | |
# 例如:(在项目文件夹中运行) | |
docker build -t test-node . |
.dockerignore 文件用于忽略 docker 中需要打包进镜像的文件
.dockerignore 示例:
# Microbundle cache | |
.rpt2_cache/ | |
.rts2_cache_cjs/ | |
.rts2_cache_es/ | |
.rts2_cache_umd/ | |
# Optional REPL history | |
.node_repl_history | |
# Output of 'npm pack' | |
*.tgz | |
# Yarn Integrity file | |
.yarn-integrity |
多个容器相互通信:
要点:Docker 中每一个 container 应该只完成一个工作,并且将它做好。
优点:
- 解耦,这样不同的服务和后端代砀都可以完全分离开来,方便管理以及未来的扩展。
- 服务的更新以及升级都是完全独立的。
- 在一个 container 中,启动多个不同的进程,需要一个进程管理器
通信过程:
docker 容器之间不能直接进行访问,而是应该通过 docker 网络进行访问。
# 创建 docker 网络 | |
docker network create test | |
# 在创建的 docker 网络中启动服务 | |
docker run -d --network test --name mongo -p 27017:27017 mongo | |
# 将原来项目中的的 ip 地址替换为 docker 的 name 名称 | |
# 例如原来为:mongodb://localhost:27017/api 的地址要替换为: mongodb://mongo:27017/api | |
# 只有在同一个 docker 网络中启动的项目间才能进行访问。 | |
docker run -d --network test --name use -p 80:3000 use |
如果每个容器都要这样操作一遍就会显得非常麻烦,这时就需要使用 Docer compose 工具(配置 docker-compose.yml 文件)
Docker compose 工具
Docker compose 是 Docker 官方推出的工具,用来管理和共享多个容器的应用,Mac 系统和 Windows 系统安装客户端时自带。Linux 需要单独安装。
docker-compose version |
配置:
- docker compose 通过一个特殊的 yml 文件,进行配置,这个文件必须命名为 docker-compose.yml
- docker-compose 所有的字段参考文档:https://docs.docker.com/compose/compose-file/compose-file-v3/
docker-compose.yml 文件配置示例:
version: '3' # docker 指令版本 | |
services: # 要启动的服务 | |
test-mongo: # 服务名称,这里的服务名称对应着容器通信时的前缀! | |
image: mongo # 使用的镜像名称 | |
container_name: test-mongo # 容器名称 | |
volumes: # 使用的数据卷映射 | |
- '.docker-volumes/mongo/data:/data/db' | |
ports: # 端口映射 | |
- 27017:27017 | |
environment: # 设置环境变量 | |
- MONGO_INITDB_ROOT_USERNAME=admin # 内置的环境变量,可以初始化添加一个 User | |
- MONGO_INITDB_ROOT_PASSWORD=pass | |
env_file: # 设置环境变量文件,将敏感信息放置到环境变量文件中 | |
- .env | |
test-use: # 第二个项目,注意对齐关系 | |
depends_on: # 配置所依赖的服务 | |
- test-mongo | |
build: # 设置构建配置 | |
context: . # 操作上下文为当前目录 | |
dockerfile: Dockerfile # 基于 Dockerfile 进行构建 | |
image: test-use-image | |
container_name: test-use | |
ports: | |
- 7001:7001 |
启动以及关闭:
# 启动 | |
docker-compose up -d | |
# 关闭 | |
docker-compose down |
# 数据库配置
数据库准备工作
- 数据库配置,初始化工作,比如插入一些特定的数据
- 避免使用 root 用户去启动服务,从而提高安全性(配置数据库访问权限)
特殊的初始化数据库的位置:/docker-entrypoint-initdb.d(这个文件夹中的脚本会在容器启动前自动执行)
可以创建 js 文件或者 sh 文件(shell)进行执行。
mongoDB:https://hub.docker.com/_mongo
Postgres:https://hub.docker.com/_lpostgres
特别注意,只有在数据库没有被创建的情况下,也就是数据库的文件夹是空的情况下,脚本才会被执行。
docker-compose.yml 文件中配置 env_file 为当前文件夹下的.env 文件。
可以使用 js 文件或者 sh 文件,但是由于此文件在其余文件之前运行,此时 js 文件中通过 process.env 获取不到所需要的环境变量,可以选用 sh 文件。
Shell 中 EOF<< 的用法
在 Shell 中我们通常将 EOF 与 < 结合使用,表示,二债的输入作为子命令或子 Shell 的输入,直到遇到 EOF 为止,再返回到主调 Shell。.
#!/bin/bash | |
mongo <<EOF | |
use admin | |
db.auth('root','123456') | |
use lego | |
db.createUser({ | |
user: '$MONGO_DB_USERNAME', | |
pwd: '$MONGO_DB_PASSWORD', | |
roles: [{ | |
role: 'readWrite', | |
db: 'lego' | |
}] | |
}) | |
db.createCollection('works') | |
db.works.insertMany([ | |
{ | |
id:19, | |
title:'测试标题', | |
name:'张三' | |
} | |
]) | |
EOF |
# 优化镜像大小
Docker 镜像构建优化:使用 alpine 版本的镜像
优化镜像大小 : 什么是 Alpine Linux:https://alpinelinux.org
Alpine 的优点
Small 小
默认软件包,alpine 选择 busybox
C 运行库,一般会用 glibc,alpine 选择 musl
最简依赖,Simple
很多内置软件的插件都去掉。
国际化内容都被删除
Secure 安全
使用 alpine 版本的镜像可以大大减小镜像的体积。
DockerBuild 构建提速
docker 中运行命令是基于一层一层的,当修改文件之后,COPY 后的缓存全部失效,这时就会重新执行后续命令,使用不了缓存,导致构建速度很慢。此时可以将原来 COPY 文件夹,改为 COPY 具体的文件(进行拆分),以更好地使用缓存。
# 部署
安装 Docker(有的云服务可以自定义安装)
Ubuntu:(需要使用 root 账户进行安装)
- https://www.runoob.com/docker/ubuntu-docker-install.html
- https://docs.docker.com/engine/install/ubuntu/
配置用户组
因为是 root 安装,普通用户执行对应的命令的时候有可能会报错:Can't connect to docker daemonGot permission denied while trying to connect to the Docker daemonsocket at unix:///var/run/docker.sock
需要将对应的用户添加到 docker 的用户组中。
#usermod 命令修改用户账户 | |
#a--append 添加 - G--groups | |
组的名称 | |
sudo usermod-aG docker 你的用户名 | |
#如果组不存在,添加对应的 docker 组 | |
sudo groupadd docker | |
#查看一个用户所属的组 | |
groups |
添加下载镜像:
# root | |
vim /etc/docker/daemon.json | |
{ | |
"registry-mirrors": | |
"https://docker.mirrors.ustc.edu.cn/", | |
"https://reg-mirror.qiniu.com" | |
] |
运行:
# 拉最新的代码 | |
git pull | |
# 先查看目前端口是否被占用 | |
# 如果被占用,释放端口 | |
# 或者改变 docker-compose,yml 的映射端口 | |
docker-compose up -d |
# YAML 语言
YAML
(YAML Ain't a Markup Language) 是一种标记语言,它使用空格作为缩进,看起来非常的简洁,可读性非常的好,非常适合一些内容大纲和配置文件。他最终是通过工具转化为 JSON 文件的,但是 YAML 的可读性比 JSON 强很多,因此复杂的配置文件一般使用 YAML。
例如:
# 字符串不用加引号 | |
key: value | |
number: 100 | |
boolean: true | |
# 字符串不用加引号,但是加上也不会报错 | |
quote_string: 'quote String' | |
# 多行字符串使用 literal block 语法:也就是竖线 | |
mutiple_string: | | |
line one | |
line two | |
line three | |
# collection types 集合类型 | |
# 使用缩进表示层级关系,最好使用两个空格,不是两个空格也没关系,对齐就行 | |
person: | |
name: dmq | |
age: 18 | |
address: | |
city: 上海 | |
# sequences 数组或者列表 | |
hobbies: | |
- Item 1 | |
- Item 2 | |
- name: weson | |
value: xyz | |
address: | |
city: 北京 |
# Github Action
Github 官方的 CI/CD 工具,作为 github 的亲儿子,和 github 几乎是完美的无缝衔接的,功能非常强大。
CI CD 常用工具:
- Github actions https://docs.github.com/en/actions
- Travis https://www.travis-ci.com/
- CircleCl https://circleci.com/
- Jenkins https://www.jenkins.io/
- 优势讨论:https://www.zhihu.com/question/306195033/answer/1870322118
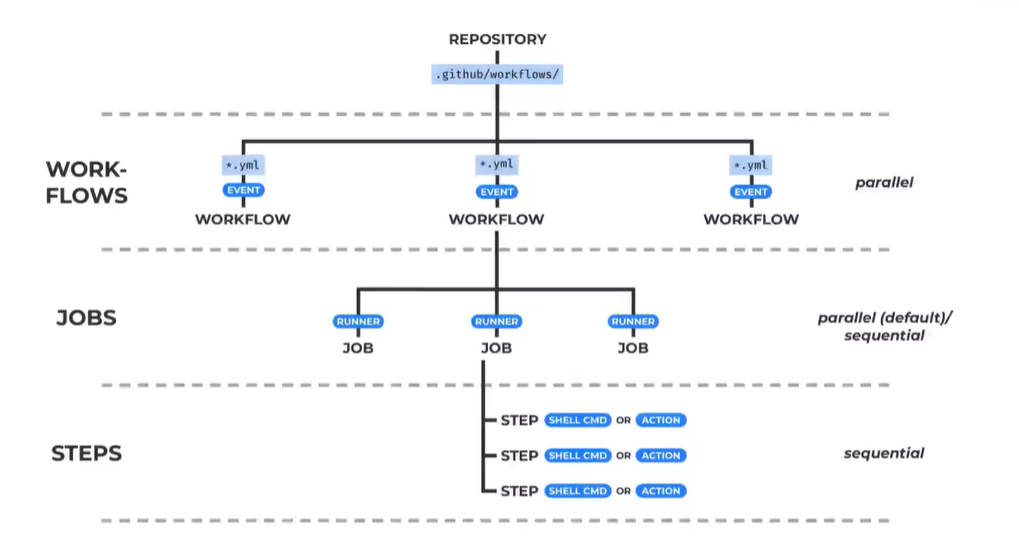
Workflow
https://docs.github.com/cn/actions/learn-github-actions/understanding-github-actions#workflows
Workflow 是一个可配置的自动化流程,可以包含多个 jobs, 通过一个在 repo 当中的 yml 文件来定义对应的流程,一个 repo 可以包含多个 workflow。
Events
Event 是触发 workflow 的特殊事件,比如 pull request,push 或者 issue, 也可以完全自定义,完整列表请看:https:/docs.github.com/cn/actions/learn-github-actions/events-that-trigger-workflows
Jobs
Job 是 Workflow 当中一系列的可执行步骤,每个 Job 是在同一个 runner 中进行的((Runner 是指处于 github 的一台特殊的虚拟机,支持各种操作系统),每个步骤或者是一个 shell 脚本,抑或是一个可执行的 action, 每个步骤是按顺序执行,并且互相依赖的。

Actions
Action 是 github actions 中的一个自定义应用,它可以运行一系列复杂的并且常用的任务,使用 action 可以帮我们减少在 workflow 中写重复代码,Github 提供了非常多常用的 action, 可以在这里查阅,同时我们也可以写自己的 action。
github secrets
项目中有的私密信息不希望公开暴露,通常的做法是将私密信息写道 env 文件中,使用 gitingore 将其忽略掉,这里还有一个做法就是 github secrets,在 github 官网设置 github secret,然后在文件中直接书写变量。
例如:.github 文件夹下 workflow 文件夹下创建一个 yml 文件,写入:
name: Github Actions Demo | |
on: [push] | |
jobs: | |
Check-Github-actions: | |
runs-on: ubuntu-latest | |
steps: | |
- run: echo "triggered by a $<!--swig5--> event" | |
- run: echo "running on a $<!--swig6--> server hosted by github" | |
- name: check out repo code | |
uses: actions/checkout@v2 # 在工作流程中检出代码仓库的内容、确保工作流程始终使用一致的代码版本 | |
- run: echo "the $<!--swig7--> has been cloned" | |
- name: List files in the repo | |
run: | | |
ls $ | |
build: | |
runs-on: ubuntu-latest | |
steps: | |
- uses: actions/checkout@v2 | |
width: | |
repository: 'vikingmute/lego-bricks' | |
- name: List files in the repo | |
run: | | |
ls $ | |
- uses: actions/setup-node@v2 | |
with: | |
node-version: '16' | |
- run: node -v | |
- run: npm install -g typescript | |
- run: tsc -v | |
jobs: | |
SECRET-SSH-ACTIONS: | |
runs-on: ubuntu-latest | |
steps: | |
#使用 ssh-action 完成远程登陆:文档地址:https://github.com/appleboy/ssh-action | |
- uses: appleboy/ssh-action@master | |
with: | |
host: $<!--swig10--> | |
username: $ | |
password: $ | |
script_stop: true | |
script: | | |
pwd | |
ls -l | |
touch secret.txt | |
echo $ >> secret.txt |
# 自动化部署
# 推送远程镜像仓库
普通线上更新流程:
# 每次代码更新以后,登录到 ssh 服务器 | |
# 关闭服务 | |
docker-compose down | |
# 更新代码 | |
git pull | |
# 假如有.env,的更新需要重新设置,env 文件 | |
# 重新 build 应用镜像 | |
docker-compose build lego-backend | |
# 重启服务 | |
docker-compose up -d |
弊端:
初次上线和更新属于两步
初次上线需要特别的操作,就是之前手动部署上线的运行的过程
clone 代码
设置环境变量.env
docker-compose up -d
追求的成果:
每次提交,可以自动一次性的部署到任何服务器,实现初次启动或者更新的效果,这才是一个完美的 develops 的流程
解决方案:
将上面本地的镜像存到 docker hub 服务器中,这样每次就不用重新 build,而是直接拉取。
services: | |
lego-redis: | |
image:redis:6 | |
lego-mongo: | |
image:mongo:latest | |
lego-backend: | |
image:lego-backend | |
#我们需要每次手动的 build 镜像,也就说镜像只存在于本地 | |
build: | |
......context:. | |
dockerfile:Dockerfile |
改为:
# 更好的方案 | |
# 不需要任何代码库中的文件,只需要一个 docker-compose.yml 文件 | |
# 就可以轻松的在任何服务器运行 | |
services: | |
lego-redis: | |
image:redis:6 | |
lego-mongo | |
image:mongo:latest | |
lego-backend: | |
# 不需要 build, 而是存在于 docker hub 服务器中,可以每次直接拉取 | |
image:lego-backend:1.0.1 |
docker hub 免费版有限制,推荐使用阿里云容器镜像服务:
阿里云容器镜像服务 ACR
个人版完全免费
创建镜像仓库之后,需要将本地镜像推送到 ACR 仓库中:
# 来到镜像仓库的基本信息页面 | |
# 登录 | |
docker login --username=用户名 registry.cn-hangzhou.aliyuncs.com | |
# tag 两种方式: | |
# 1: 使用 tag bui1d | |
docker build--tag "registry.cn-hangzhou.aliyuncs.com/dmq00/test:[镜像版本号]" | |
# 2: 给 build 好的打 tag | |
docker tag [ImageId] registry.cn-hangzhou.aliyuncs.com/dmq00/test:[镜像版本号] | |
# 查看镜像是否 build 完成 | |
docker images | |
# 推送镜像 | |
docker push registry.cn-hangzhou.aliyuncs.com/dmq00/test:[镜像版本号] | |
# 在阿里云 ACR 界面检查看是否已经存在 |
# Github Actions 自动部署
使用 github actions 加成自动化部署:当推送代码到 github 仓库时,让我们的代码自动提交镜像到镜像仓库。
大体分为两步
# 在 github 服务器上 build image 并且 push
使用 docker-compose-online 文件在服务器上运行应用
第一步详细流程分析,在 github runner 上运行
checkout 代码(在 github 服务器上)
创建.env 文件,并且添加两个环境变量 (upload to OSS 需要两个对应的信息)
使用阿里云 ACR 完成 docker login
使用正确的阿里云 tag 进行 docker build
- 怎样每次 push 生成特殊的 tag?是一个后续的问题
docker push
例如:【1】在项目文件夹.github/workflow 下创建 yml 文件,写入:
name: build image,push to ACR | |
on: [push] | |
jobs: | |
build-and-push: | |
runs-on: ubuntu-latest | |
steps: | |
# checkout 代码 | |
- uses: actions/checkout@v2 | |
# 创建 env 文件 | |
- run: touch .env | |
# 使用 “>> ” 添加信息 | |
- run: echo ALC_ACCESS_KEY=$<!--swig14--> >> .env | |
- run: echo ALC_SECRET_KEY=$<!--swig15--> >> .env | |
# 使用阿里云 ACR 完成 docker login | |
- name: Login to Aliyun ACR | |
uses: aliyun/acr-login@v1 # 使用专属的镜像 | |
with: | |
login-server: https://registry.cn-hangzhou.aliyuncs.com | |
region-id: cn-hangzhou # 查看官网自己仓库的信息 | |
username: "$" | |
password: "$" | |
# 使用正确的阿里云 tag 进行 docker build | |
- name: Build image for Docker | |
run: docker build --tag "registry.cn-hangzhou.aliyuncs.com/dmq00/test:0.0.2" | |
- name: Push Image to ACR | |
run: docker push registry.cn-hangzhou.aliyuncs.com/dmq00/test:0.0.2 |
这样就能保证代码 push 到 github 上之后自动将镜像推送到 docker 镜像仓库,结合 dockerfile 文件就能保证使用 docker 镜像时自动执行命令,安装对应依赖并执行项目。
第二步详细流程分析,在服务器上部署对应的代码并且运行
checkout 代码
创建.env 文件,添加多个环境变量。(应用所有需要的环境变量),github secrets 中添加。
创建文件夹,拷贝如下文件到文件夹内
- .env
- docker-compose-online.yml
- mongo-entrypoint 文件夹
将新建的文件夹拷贝到服务器 (SCP) 当中
- 使用 https://github.com/appleboy/scp-action
SSH 到服务器中
- 进入拷贝的文件夹内
- 登录阿里云 ACR
- 停止服务 docker-compose down (第一次的话,没有启动也不会报错)
- 启动服务 docker-compose up
- 清理工作可选,保证安全(删除.env 文件,登出 docker 账户)
后续过程需要完成:
在 push tags 的时候才触发对应的 job
:https://docs.github.com/cn/actions/learn-github-actions/events-that-trigger-workflows
怎样获取对应的每次提交相关的特殊信息
:https://docs.github.com/en/actions/learn-github-actions/contexts
使用这个特殊信息,在对应的 docker-compose-online.yml 中进行替换,将要启动的版本替换为将要构建的版本。