# 需求分析
为什么需要优化研发流程?
- 项目量级增加:几干行代码 -> 几万行代码
- 项目数量扩大:几个项目 -> 几干个项目
- 项目复杂度高:Wb 项目 ->H5/PC/ 小程序 / 后端 / 脚手架
- 团队人数增长:几个人 -> 几百人
- 传统的项目研发流程已经无法满足业务需求
# git 开发流程
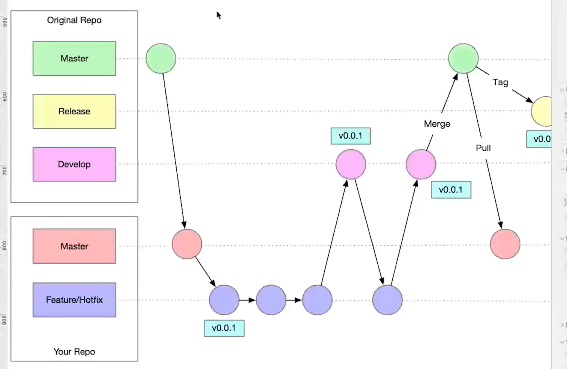
单人 git 项目开发流程
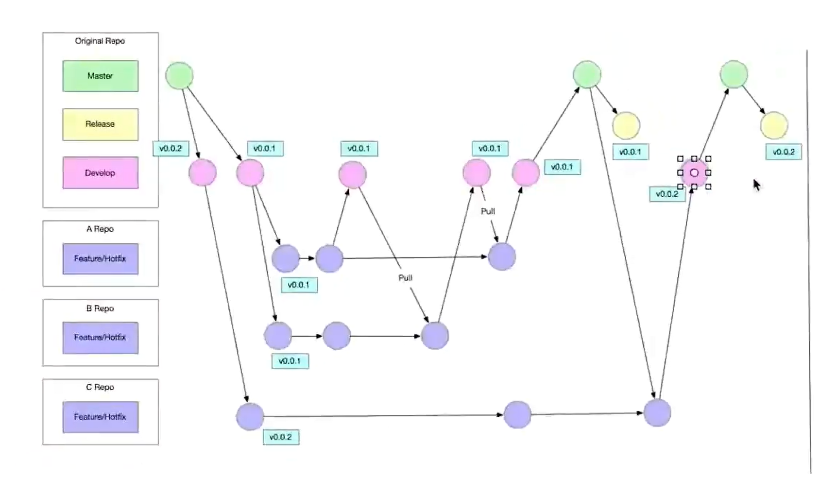
多人 git 项目开发流程
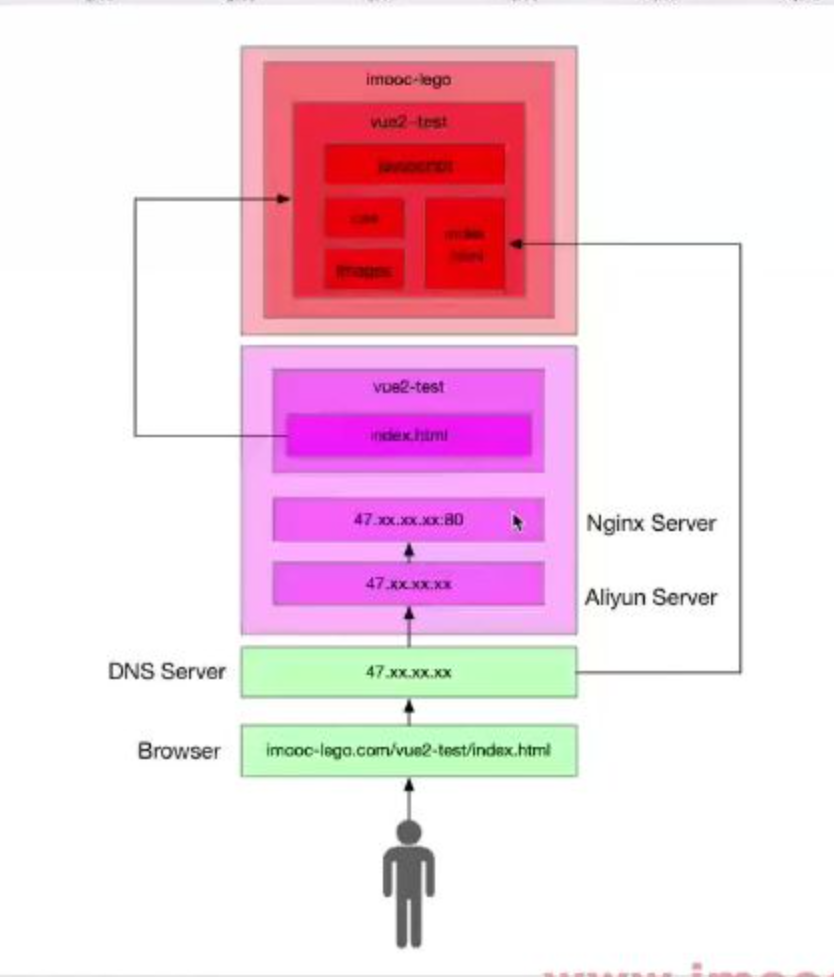
# 浏览器获取资源步骤
项目创建流程思考
当团队较大时,让每一个团队成员开发创建项目体验趋于一致就非常重要。
项目创建流程
- 项目代码
- 抽象出项目模板
- 存储到数据库
- 脚手架读取数据库
- 根据脚手架创建新的项目
提升前端研发效率的手段
- 物料和模板
- 低代码搭建
- 等等
从使用角度理解什么是脚手架?
# 脚手架简介
脚手架本质是一个操作系统的客户端,它通过命令行执行,比如:
vue create vue-test-app |
上面这条命令由 3 个部分组成:
- 主命令:vue
- command:create
- command 的 param:vue-test-app
它表示创建一个 vue 项目,项目的名称为 vue-test-app, 以上是最一个较为简单的脚手架命令,但实际场易
往更加复杂,比如:
当前目录已经有文件了,我们需要覆盖当前目录下的文件,强制进行安装 ue 项目,此时我们就可以输入:
vue create vue-test-app --force |
这里的 - force 叫做 option, 用来辅助脚手架确认在特定场景下用户的选择(可以理解为配置)。还有一种场景
通过 vue create
创建项目时,会自动执行 npm install 帮用户安装依赖,如果我们希望使用淘宝源来安装,
可以输入命令:
vue create vue-test-app --force -r https://registry.npm.taobao.org |
这里的 - x 也叫做 option, 它与 --force 不同的是它使用 -,并且使用简写,这里的 - x 也可以替换成 --registry, 有的同学可能要问,为什么老师知道这个命令,其实我们输入下面的命令就可以看到 vue create 支持的所有 options:
vue create --help
-r https:/registry.npm.taobao.org 后面的 https://registry.npm.taobao.org 成为 option 的 param, 其实任 - force 可以理解为:-force true,f 简写为:--force 或 - f
# 脚手架原理
脚手架的执行原理如下:
- 在终端输入 vue create vue-test-app
- 终端解析出 vue 命令
- 终端在环境变量中找到 ue 命令
- 终端根据 vue 命令链接到实际文件 vue.js
- 终端利用 node 执行 `ue.js
- vue.js 解析 command/options
- vue.js 执行 command
- 执行完毕,退出执行
从应用的角度看如何开发一个脚手架
这里以 vue-cli 为例:
- 开发 npm 项目,该项目中应包含一个 bin/vue.js 文件,并将这个项目发布到 npm
- 将 npm 项目安装到 node 的 lib/node_modules
- 在 node 的 bin 目录下配置 vue 软链接指向 lib/node modules/Qvue/cli/bin/vue.js
- 这样我们在执行 vue 命令的时候就可以找到 vue.js 进行执行
还有很多疑问需要解答
为什么全局安装 vue/cli 后会添加的命令为 vue? (npm install -g @vue/cli)
答:vue/cli 项目的 package.json 中的 bin 字段配置的名称为 vue。
全局安装 vue/c1i 时发生了什么?
答:全局 node_modules 中下载项目文件,并根据项目 package.json 中的 bin 字段配置可执行文件软链接。
为什么 vue 指向一个 js 文件,我们却可以直接通过 vue 命令直接去执行它?
答:js 文件配置了蛇棒(操作系统的接口),例如:
#!/usr/bin/env node通常使用环境变量中找 node 命令,因为每个电脑上的 node 文件位置不同,但是环境变量中都会有 node 软连接。
# 脚手架的开发流程
脚手架开发流程详解
开发流程
- 创建 npm 项目
- 创建脚手架入口文件,最上方添加 #!/usr/bin/env node
- 配置 package.json, 添加 bin 属性
- 编写脚手架代码
- 将脚手架发布到 npm
使用流程
安装脚手架
npm install -g your-own-cli
使用脚手架
your-own-cli-binName
脚手架开发难点解析
分包:将复杂的系统拆分成若干个模块
命令注册:
- vue create
- vue add- vue invoke
参数解析:
vue command [options <params>]
options: 全称:--version、--help。简写为:-v -h
帮助文档:global help
命令行交互
日志打印
命令行文字变色
网络通信
文件处理
# 开发细节
两种链接本地文件的方式
npm link 命令会将命令执行的当前文件夹根据 bin 字段软连接到全局的 node_moduls。
npm link 包名称 ,这个命令会将全局包添加软连接到当前项目的 node_modules 中。
npm unlink 包名称 ,这个命令用于移除全局 node_modules 中指定的软连接。(不过这个命令不好用,建议使用
npm uninstall -g包名称、或者npm remove -g包名称 代替)调试过程中,当本地包相互依赖时,可以使用 File: 路径进行指向。
两种方式的区别
npm link 的方式创建的软连接可以实时同步更改的文件,但是项目文件多了就不方便管理、很复杂,File 路径不能实时同步文件修改,需要执行 npm install,但是管理方便。
# 脚手架发布体系
利用脚手架统一管理发布阶段
利用脚手架做发布的优势
- 规范:利用统一发布规范,如 commit 记录、分支名称、代码规范等
- 效率:避免大量重复操作,浪费开发时间
- 安全:构建和发布全部在云端操作,避免个人发布时带来的安全隐患
脚手架发布的流程?
- GitF1low 自动化代码提交
- 远程代码自动检查
- 云端完成构建与发布操作
# 脚手架发布流程
- 检查 package.json 中 name 和 bin 字段,name 字段不能和已存在的线上包名重复,
- 检查版本号,是否需要更新
- npm login
- npm publish
# npm 新特性:workspace
作用
本地调试时,需要多次执行 npm link,node15 版本推出 workspace,workspace 新特性可以帮助我们进行多 package 包管理,可以让多个 npm 包在同一个项目中进行开发和管理:
- 将子包中所有的依赖包都提升到根目录进行安装,提升包的安装速度
- 初始化 (npm install) 后自动将子包之间的依赖进行关联
- 各个子包共享一些流程(eslint、githook、publish flow 等等)
# Lerna 多 package 管理
# Lerna 简介
原生脚手架开发痛点分析(Lerna 解决了哪些问题: )
痛点一:重复操作
- 多 Package 本地 link
- 多 Package 依赖安装
- 多 Package. 单元测试
- 多 Package 代码提交
- 多 Package 代码发布
痛点二:版本一致性
- 发布时版本一致性
- 发布后相互依赖板本升级
- package 越多,管理复杂度越高
简介:
Lerna 是一个优化基于 git+npm 的多 package 项目的管理工具。
优势:
- 大幅减少重复操作
- 提升操作的标准化
Lera 是架构优化的产物,它揭示了一个架构真理:项目复杂度提升后,就需要对项目进行架构优化。优化的主要目标往往都是以效能为核心。
# Lerna 使用
Lerna 开发脚手架流程如下:
npm 上创建 group
初始化 npm 项目
安装 lerna
package.json 中配置 workspaces
"workspaces": [
"packages/*"],
//workspaces 字段允许指定一个或多个目录作为工作区。一、可以在父级目录的 package.json 中管理他们的依赖,从而较少体积。二、工作区每个包之间直接相互引用,有助于提高开发效率。三、工作区所有包共享版本控制历史。lerna init 初始化项目(创建了 git)
配置 gitignore 排除不需要提交的文件
--------------------------- 初始化完成
lerna create 创建 package
lerna add 安装依赖(最新版废弃),使用 npm install <dependency> --workspace <workspace > 代替。
lerna link 链接依赖(最新版废弃),workspace 自动链接。
---------------------------- 项目创建完成
lerna exec 执行 shell 脚本
lerna run 执行 npm 命令
lerna clean 清空依赖
lerna bootstrap 重装依赖(最新版废弃),使用 npm install 代替
---------------------------- 项目开发完成
git push 提交到远程仓库
lerna version 升级版本号
lerna changed 查看上版本以来全部的变更。
git add . 添加到 git 工作区
lerna diff 查看 diff
lerna publish 进行项目发布
// 默认是私有仓库,需要在 package.json 中进行配置:"publishConfig": {
"access":"public"
}---------------------------- 项目发布完成
这里注意 npm 最新版 workspace 特性的推广导致 lerna 许多命令在最新版被废弃。
# Lerna 学习收获
- 熟悉 Yargs 脚手架开发框架
- 熟悉多 Package 管理工具 Lerna 的使用方法和实现原理
- 深入理解 Node.js 模块路径解析流程
# 一、yargs
脚手架构成
bin:package,json 中配置 bin 属性,npm link 本地安装
command: 命令
options: 参数 (boolean/string/number)
文件顶部增加 #!/usr/bin/env node
脚手架初始化流程
构造函数:Yargs (0
常用方法:
Yargs.options
Yargs.option
Yargs.group
Yargs.demandCommand
Yargs.recommendCommands
Yargs.strict
Yargs.fail
Yargs.alias
Yargs.wrap
Yargs.epilogue
- 脚手架参数解析
- hideBin(process.argv)/Yargs.argv
- Yargs.parse(argv,options)
- 命令注册方法
- Yargs.command(command,describe,builder,handler)
- Yargs.command({command,describe,builder,handler )
# 二、Lerna 实现原理
Lerna 是基于 git+npm 的多 package 项目管理工具
实现原理:
- 通过 import-local 优先调用本地 lerna 命令
- 通过 Yargs 生成脚手架,先注册全局属性,再注册命令,最后通过 parse 方法解析参数
- lerna 命令注册时需要传入 builder 和 handler 两个方法,builder 方法用于注册命令专属的 options
- handler 用来处理命令的业务逻辑
- lerna 通过配置 npm 本地依赖的方式来进行本地开发,具体写法是在 package.json 的依赖中写入:file:your-local--module-path, 在 lerna publish 时会自动将该路径替换
# 三、Node.js 模块路径解析流程
Node.js 项目模块路径解析是通过 require.resolve 方法来实现的
require,resolve 就是通过 Module.reso1 veFileName 方法实现的
require,resolve 实现原理:Module,resolveFileName 方法核心流程有 3 点:
判断是否为内置模块
通过 Module,resolveLookupPaths 方法生成 node_modules 可能存在的路径
通过 Module,findPath 查询模块的真实路径
Module,findPath 核心流程有 4 点:
查询缓存(将 request 和 paths 通过 \xoo 合并成 cacheKey)
遍历 paths, 将 path 与 request 组成文件路径 basePath
如果 basePath 存在则调用 fs,realPathSync 获取文件真实路径
将文件真实路径缓存到 Module.pathCache (key 就是前面生成的 cacheKey)
fs.realPathSync 核心流程有 3 点:
查询缓存(缓存的 key 为 p, 即 Module.findPath 中生成的文件路径)】
从左往右遍历路径字符串,查询到 / 时,拆分路径,判断该路径是否为软链接,如果是软链接则查询真实链接,并生成新路径 P, 然后继续往后遍历,这里有 1 个细节需要特别注意:
遍历过程中生成的子路径 base 会缓存在 knownHard 和 cache 中,避免重复查询
遍历完成得到模块对应的真实路径,此时会将原始路径 original 作为 key, 真实路径作为 value, 保存到缓存中
require.resolve,paths 等价于 Module.resolveLookupPaths,, 该方法用于获取所有 node_modules 可能存在的路径
require.resolve,paths 实现原理:
如果路径为 /(根目录),直接返回【'/node modules'】否则,将路径字符串从后往前遍历,查询到 / 时,拆分路径,在后面加上 node_modules, 并传入一个 paths 数组,直至查询不到 / 后返回 paths 数组
# yargs
yargs 使用简要介绍:
#! /usr/bin/env node | |
// 获得 yargs 构造实例 | |
const yargs = require('yargs/yargs'); | |
// 参数解析函数 | |
const { hideBin } = require('yargs/helpers'); | |
const arg = hideBin(process.argv); | |
const cli = yargs(arg); | |
// 配置命令: | |
cli | |
.usage('Usage: $0 [command] <options>') // 使用说明,$0 表示命令 | |
.demandCommand(1,'A command is required,pass --help to see info') // 最少一个次命令 | |
.strict() // 对于未知的命令行参数进行提示输出。 | |
.recommendCommands() // 查找提示近似命令 | |
.alias('h','help') //options 别名 | |
.alias('v','version') | |
.wrap(cli.terminalWidth()) // 命令行输出宽度 | |
.epilog(`welcomn use cli-core`) // 结语 | |
.options({ // 注册多个 options 选项 | |
debug:{ | |
type:"boolean", | |
describe: "bootstrap debug mode", | |
alias: "d" // 添加别名 | |
}, | |
}) | |
.option('registry',{ // 添加单个选项 | |
hidden: true, // 不对外暴露命令 | |
type:"string", | |
describe:"define global registry", | |
alias:'r' | |
}) | |
.group(['debug'],'Dev Options') // 对 Options 选项进行分类 | |
.group(['registry'],"Extra Options") | |
.command('init [name]','init a project',(yargs)=>{ // 注册次命令,制定对应 options | |
yargs | |
.option('name',{ | |
type: 'string', | |
describe: 'Name of a project', | |
alias: 'n' | |
}); | |
},(argv)=>{ | |
console.log(argv); | |
}) | |
.command({ // 第二种注册命令的方法(更加精细) | |
command: 'list', | |
aliases: ['ls','la','ll'], | |
describe: 'List local packages', | |
builder: (yargs)=>[ | |
//.... 操作 | |
], | |
handler: (argv)=>{ | |
console.log(argv); | |
} | |
}) | |
.argv; // 使用参数 |
# commander
commander 简单单例模式
#! /usr/bin/env node | |
const commander = require('commander'); | |
const pkg = require('../package.json'); | |
const { program } = commander; //commander 单例,包含已注册好的基础命令 | |
program | |
.version(pkg.version) | |
.parse(process.argv) |
commander 强大功能
#! /usr/bin/env node | |
const commander = require('commander'); | |
const pkg = require('../package.json'); | |
const program = new commander.Command();// 手动实例化一个 commander 实例 | |
program | |
.name(Object.keys(pkg.bin)[0]) | |
.usage('<command> [options]') // 使用说明 | |
.version(pkg.version) // 版本 | |
.option('-d,--debug','是否开启调试模式',false) // 配置 option 选项:选项,帮助信息,默认值 | |
.option('-e,--envName <envName>','获取变量名称')//option 获得传参 | |
.parse(process.argv) // 解析参数 | |
// 使用 command 注册命令 | |
const clone = program.command('clone <source> [destination]'); //< 必选项 >,[可选项] | |
clone | |
.description('clone a repository') | |
.option('-f,--force','是否强制克隆') | |
.action((source,destination,cmdObj)=>{ | |
console.log('do clone',source,destination,cmdObj.force); | |
}) | |
// 使用 addCommand 注册子命令 | |
const service = new commander.Command('service'); | |
service | |
.command('start [port]') | |
.description('start service at port') | |
.action((port)=>{ | |
console.log('do service start',port); | |
}); | |
service | |
.command('stop') | |
.description('stop service') | |
.action(()=>{ | |
console.log('stop service'); | |
}) | |
program.addCommand(service); | |
// 参数解释和自动匹配功能 | |
program | |
.arguments('<cmd> [options]') // 强制传入命令 | |
.description('test command',{ // 描述 | |
cmd: '命令', | |
options: '参数' | |
}) | |
.action(function(cmd,options){ // 匹配全部命令 | |
console.log(cmd,options); | |
}) | |
// 默认命令与命令转向功能 | |
program | |
.command('install [name]','install package',{ | |
executableFile: 'imooc-cli', // 将 install [name] 命令转向 imooc-cli | |
isDefault: true,// 设置为默认命令 | |
hidden: true,// 命令不可见 | |
}) | |
.alias('i'); | |
// 高级定制 1:自定义 help 信息 | |
program.helpInformation = function(){ | |
return ''; | |
}; | |
program.on('--help',function(){ | |
console.log('my help information'); | |
}); | |
// 高级定制 2:监听 debug | |
program.on('option:debug',function(){ | |
if(program.debug){ | |
process.env.LOG_LEVEL = 'verbose'; | |
}; | |
console.log(process.env.LOG_LEVEL); | |
}) | |
// 高级定制 3:监听未知命令(与默认命令冲突) | |
program.on('command:*',function(obj){ | |
console.error('未知命令:'+ obj[0]); | |
const avaliableCommands = program.commands.map(cmd=>cmd.name()); | |
console.log('可用命令:'+avaliableCommands.join(',')); | |
}) | |
// 最后要进行参数解析! | |
program.parse(process.argv) | |
// 内置属性和方法 | |
console.log(program.debug); | |
console.log(program.envName); | |
program.outputHelp();// 内置方法,弹出帮助信息 | |
console.log(program.opts());// 内置方法,返回 options 信息 |
# require 加载机制
require 直接加载.js、.json 和.node 文件,其余文件按照 js 语法进行加载
- 加载 js 文件,require 加载的 js 文件需要进行导出
- 加载 json 文件,通过 JSON.parse 进行文件解析
- 加载 node 文件,通过 process.dlopen 方法加载(node 文件是 C++ 语法)
- 其余文件,使用 js 语法加载,此时语法错误的会报错。
# node 多进程
# 介绍
进程是资源分配的最小单位,线程是 CPU 调度的最小单位
什么是进程
进程 (Process) 是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单
位,是操作系统结构的基础。
进程的概念主要有两点:
- 第一,进程是一个实体。每一个进程都有它自己的地址空间。
- 第二,进程是一个 “执行中的程序”,存在嵌套关系。
node 多进程官方文档:
中文版:http://nodeis.cn/api/child_process,html
操作系统会使用时会开辟一个 node 进程,每个 node 文件在运行时都会创建一个 child_process 进行,也就是 node.js 的子进程。
# child_precess 用法
一、执行可执行文件。
const cp = require('child_process') // 默认内置库 | |
//exec 方法,可以传执行命令,也可以传文件路径,但不支持给文件传参。 | |
cp.exec('ls -al|grep node_modules',function(err,stdout,stderr){ | |
console.log(err,stdout,stderr); | |
}); | |
//execFile 方法,传文件路径,并且支持给文件传参数。 | |
cp.execFile('ls',['-al'],function(err,stdout,stderr){ | |
console.log(err,stdout,stderr); | |
}) | |
//spawn 方法,传入文件路径,以流式的方式输出,是 exec 和 execFile 的底层原理 | |
const child = cp.spawn('npm',[install],{ | |
cwd: path.resolve('/User/dmq/Desktop/test') | |
}); | |
child.stdout.on('data',function(chunk){ | |
console.log('stdout',chunk.toString()); | |
}); | |
child.stderr.on('data',function(chunk){ | |
console.log('stderr',chunk.toString()); | |
}) |
exec 和 spawn 使用场景:
当文件操作过程复杂,并且需要频繁输出日志时,使用 spawn 进行流式操作。
const child = cp.spawn('npm',[install],{ | |
cwd: path.resolve('/User/dmq/Desktop/test'), | |
stdio: 'inherit', // 将输出传给父进程。 | |
}); | |
// 监听错误事件 | |
child.on('error',e=>{ | |
console.error(e.message); | |
}) | |
// 监听退出事件 | |
child.on('exit',e=>{ | |
console.log('命令执行成功' + e) | |
}) | |
child.stdout.on('data',function(chunk){ | |
console.log('stdout',chunk.toString()); | |
}); | |
child.stderr.on('data',function(chunk){ | |
console.log('stderr',chunk.toString()); | |
}) |
当文件操作过程简单,需要直接输出时,使用 exec 方法
cp.exec('npm install',{ | |
cwd: path.resolve('/User/dmq/Desktop/test') | |
},function(err,stdout,stderr){ | |
console.log(err); | |
console.log(stdout); | |
console.log(stderr); | |
}) |
二、执行指定 JS 文件(不支持回调)
fork 方法类似于 require 函数,但是区别在于 fork 方法会创建一个 node 子进程执行 JS 文件,使用独立的 v8 引擎去解析代码。
index.js 文件:
const child = cp.fork(path.resolve(__dirname,'child.js')); | |
child.send('hello child process!',()=>{ | |
child.disconnect(); // 及时断开连接,防止主进程和子进程长期处于等待状态 | |
}); | |
child.on('message',(msg)=>{ | |
console.log(msg); | |
}); | |
console.log('main pid:',process.pid); |
child.js 文件:
console.log('child process pid:',process.pid); | |
process.on('message',(msg)=>{ | |
console.log(msg); | |
}); | |
process.send('hello main process'); |
# child_process 源码
疑问:
- exec、execFile、spanwn 和 fork 区别:
- exec: 原理是调用 /bin/sh-c 执行我们传入的 shell 脚本,底层调用了 execFile
- execFile: 原理是直接执行我们传入的 file 和 args, 底层调用 spawn 创建和执行子进程,并建立了回调,一次性将所有的 stdout 和 stderr 结果返回
- spawn: 原理是调用了 internal/child_.process, 实例化了 ChildProcess 子进程对象,再调用 child.spawn 创建子进程并执行命令,底层是调用了 child._handle.spawn 执行 process_wrap 中的 spwn 方法,执行过程是异步的,执行完毕后通过 PIPE 进行单向数据通信,通信结束后会子进程发起 onexit 回调,同时 Socket 会执行 close 回调
- fork: 原理是通过 spawn 创建子进程和执行命令,通过 setupchannel 创建 IPC 用于子进程和父进程之
# egg.js+mongodb
1、egg.js
用于快速生成后端 api 的框架。
2、npm init egg 命令
当执行 npm init egg 命令时,npm 会自动找到 create-egg 这个包(其他包同理,找到 create - 包名),进行执行。当不想将脚手架安装到本地,而是在线上直接使用时,这个机制就显得十分重要。
3、mongodb 数据库
非关系型数据库。
云 mongodb
云 mongodb 开通
地址:https:/mongodb.console.aliyun.comL, 创建实例并付款即可
本地 mongodb
地址:https:/www.runoob.com/mongodb/mongodb-tutorial.html
mongodb 使用方法
https://www.runoob.com/mongodb/mongodb-databases-documents-collections.html
4、egg.js 链接 mongodb 数据库
utils/mongo.js
'use strict'; | |
const logger = require('npmlog'); | |
logger.level = process.env.LOG_LEVEL ? process.env.LOG_LEVEL : 'info'; | |
logger.heading = 'pick'; // 自定义头部 | |
logger.addLevel('success', 2000, { fg: 'green', bold: true }); // 自定义 success 日志 | |
logger.addLevel('notice', 2000, { fg: 'blue', bg: 'black' }); // 自定义 notice 日志 | |
const MongoClient = require('mongodb').MongoClient; | |
class Mongo { | |
constructor(url, dbName) { | |
this.url = url; | |
this.dbName = dbName; | |
} | |
connect() { | |
return new Promise((resolve, reject) => { | |
MongoClient.connect( | |
this.url, | |
{ | |
useNewUrlParser: true, | |
useUnifiedTopology: true, | |
}, | |
(err, client) => { | |
if (err) { | |
reject(err); | |
} else { | |
const db = client.db(this.dbName); | |
resolve({ db, client }); | |
} | |
}); | |
}); | |
} | |
connectAction(docName, action) { | |
return new Promise(async (resolve, reject) => { | |
const { db, client } = await this.connect(); | |
try { | |
const collection = db.collection(docName); | |
action(collection, result => { | |
this.close(client); | |
logger.verbose('result', result); | |
resolve(result); | |
}, err => { | |
this.close(client); | |
logger.error(err.toString()); | |
reject(err); | |
}); | |
} catch (err) { | |
this.close(client); | |
logger.error(err.toString()); | |
reject(err); | |
} | |
}); | |
} | |
query(docName) { | |
return this.connectAction(docName, (collection, onSuccess, onError) => { | |
collection.find({}, { projection: { _id: 0 } }).toArray((err, docs) => { | |
if (err) { | |
onError(err); | |
} else { | |
onSuccess(docs); | |
} | |
}); | |
}); | |
} | |
insert(docName, data) { | |
return this.connectAction(docName, (collection, onSuccess, onError) => { | |
collection.insertMany(data, (err, result) => { | |
if (err) { | |
onError(err); | |
} else { | |
onSuccess(result); | |
} | |
}); | |
}); | |
} | |
remove(docName, data) { | |
return this.connectAction(docName, (collection, onSuccess, onError) => { | |
collection.deleteOne(data, (err, result) => { | |
if (err) { | |
onError(err); | |
} else { | |
onSuccess(result); | |
} | |
}); | |
}); | |
} | |
// update(collection, data) { | |
// } | |
close(client) { | |
client && client.close(); | |
} | |
} | |
module.exports = Mongo; |
db.js
const mongo = new Mongodb('mongodb://dmq:dmq0216@127.0.0.1:27017/dbName','dbName'); | |
const data = mongo().query('project'); |
# inquirer 源码
# 学习路径
- 掌握一些库:readline(命令行读取)/events(事件驱动)/stream(输入输出流)/ansi-escapes(命令行文字样式)/rxjs(处理异步事件)
- 掌握命令行交互的实现原理,并实现一个可交互的列表
- 分析 inquirer 源码掌握其中的关键实现
# ejs+glob
ejs 三方库用于 xml 动态模板渲染,glob 三方库用于根据 文件路径进行遍历和匹配文件 ,拿到文件的内容。
# ejs 源码
省略,详见官网
# require 源码
省略,详见官网
# 代码复用实践
** 代码复用目的:** 提高人效,降低开发成本。
计算公式为:节约工时 = 服用代码节约时间 * 代码复用系数 * 复用次数
背后思考:
- 不同开发者、团队之间会产生了大量重复、通用的代码
- 这些代码散落在各自团队的项目代码里
- 复用的时候大家习惯于直接拷贝这些代码到项目中,因为这样做对个人成本最低(开发者往往更熟悉自己写的代码),但是这种做法不利于团队之间代码共享,因为每个人开发不同的业务,对不同页面的熟悉程度不一样,而代码复用的宗旨就是要尽可能将团队中的开发着的整体水平拉齐
- 所以需要通过工具化的方式降低代码复用的成本