# v8 执行 JS
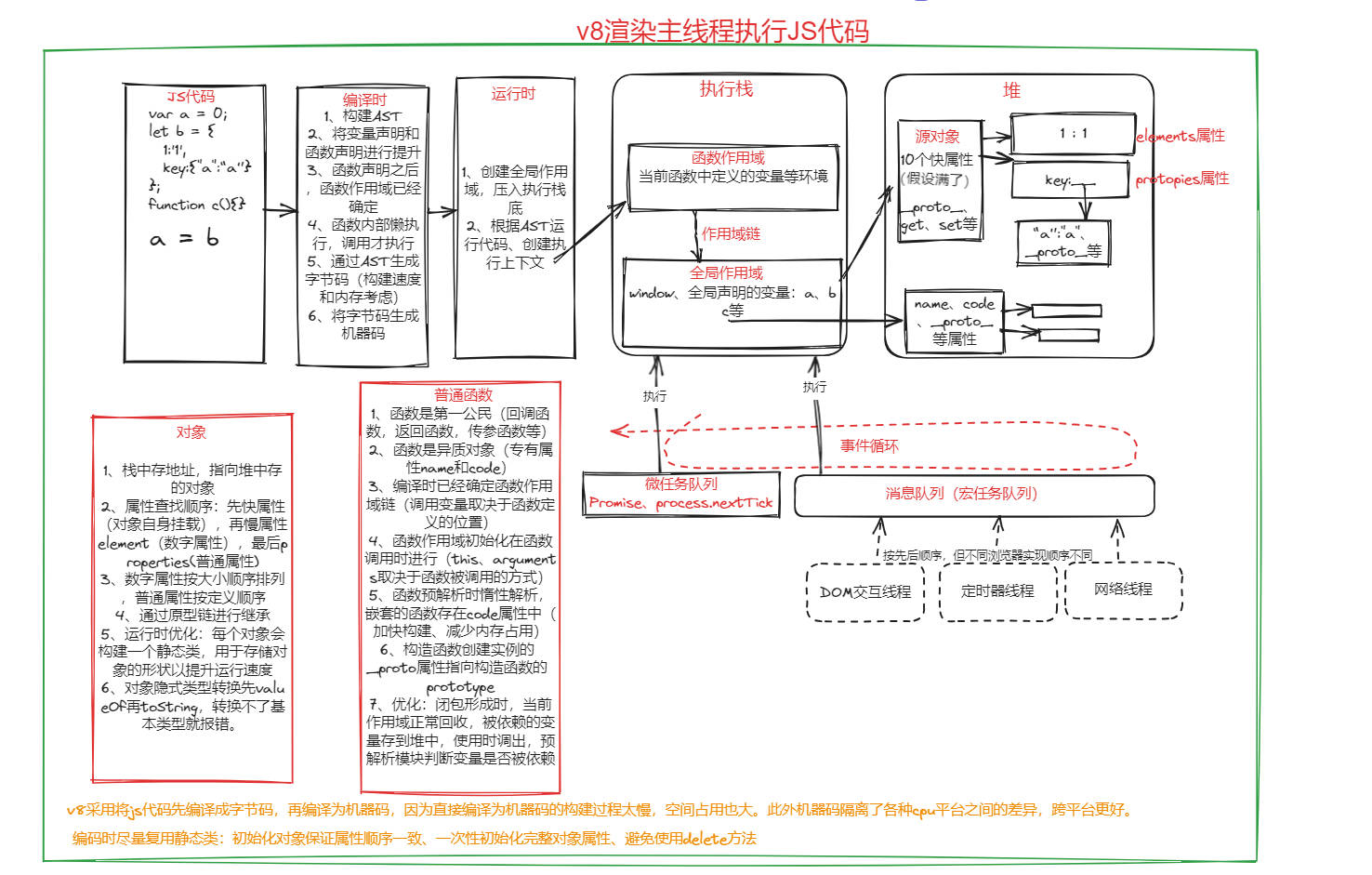
# v8 引擎介绍
Blink 内核用于解析 HTML、DOM、CSS 渲染、嵌入了 v8 引擎用于解析 Javascript
V8 是谷歌的开源高性能 JavaScript 和 WebAssembly 引擎,用 C++ 编写。它被用于 Chrome 和 Node.js 等。用于解析并执行 JavaScript 代码。
# 执行过程
- 初始化运行环境
- 堆栈空间
- 全局执行上下文
- 全局作用域
- 事件循环系统
- 利用 Scanner 扫描器将输入的代码词法分析成 tokens
- 分析的结果就是一个个的 tokens 对象组成的数组
- 分析的过程利用了有限自动状态机的概念
- 利用 parser 解析器将 tokens 转化为抽象语法树
- 根据分析 tokens 构造出一种树形关系结构
- 预解析:在 JS 代码执行之前对代码进行可选的预处理,用于提高执行效率
- 延迟解析:只有代码执行到的部分才会去解析,节省了不必要的时间和开销,提高了 JavaScript 的执行效率,其中 vite 脚手架就是利用了这个优点(还有 esbuild 打包快的优势),提高了效率。
- 利用
ignation解释器将 AST(抽象语法树)转为字节码(不直接转为机器码?)- 当年 v8 以超越同行 10 倍的运行速度而备受青睐,其本质原因是当时 v8 将 JS 源码直接编译为机器码,使得首次运行速度和后续执行速度都很快,但也存在一个问题就是内存占用太大,并且编译时占用太多时间
- 字节码使得 v8 能够很好的进行优化与反优化,当执行代码时,对机器码的存储和复用等操作时都十分繁琐 (存储占用大,分析繁琐等), 但是分析字节码就更加容易一些
- 字节码跨平台能力强
- 字节码更快的加载和解析执行
- 动态优化易操作
- 代码安全性
- 利用
TurboFan编译器将字节码转为 CPU 和 ARM 识别的机器码
# v8 中的对象结构
# 索引属性和命名属性
- v8 中的对象主要分为三个指针构成的,分别是:隐藏类、索引属性和命名属性。
- 对象的属性数字会从小到大排列,字符串会按照原创建顺序
- 对象中数字属性被称为索引属性,字符串属性被称为命名属性
- 索引属性存在 elements 中,命名属性存在 properties 中。
# 快属性和慢属性
(也称为对象内属性和普通属性)
- JS 对象很多属性是在原型链上进行查找,这样就会很慢,v8 将部分常规属性(10 个)直接存储到对象本身(对象内属性),以提高属性的查询效率。
- 快属性容量是 10 个。
# 封装、继承、多态
- 封装就是将抽象出来的数据和对数据的操作封装在一起,数据在内部被保护,程序其他部分只有通过成员才能对数据进行操作。
- 继承:有原型链继承、寄生继承和 call、apply 借用法继承。
- 多态就是函数重载:同一个函数可以根据调用的情况(参数类型和数量等)来进行不同的操作。
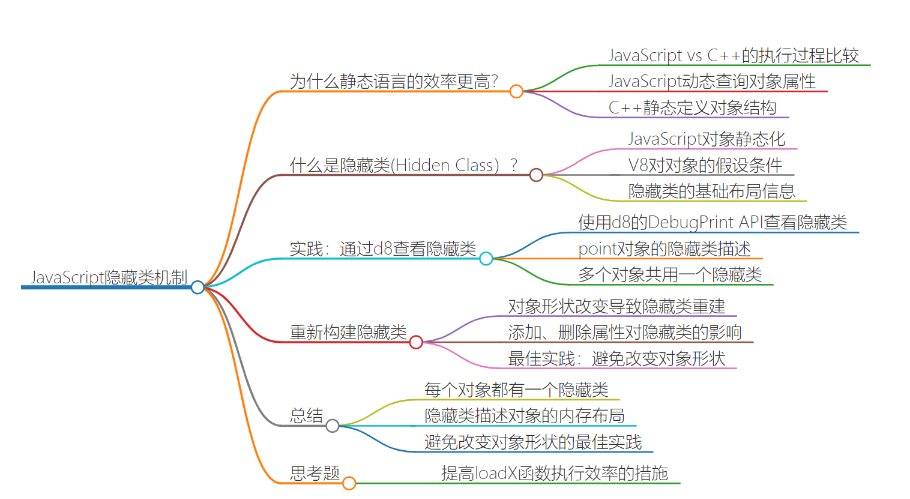
# 隐藏类
JavaScript 是一门动态语言,其各种不确定性导致 JavaScript 的执行效率要远低于静态语言,V8 为了提升 JavaScript 的执行效率,借鉴了很多静态语言的特性,比如:JIT 机制,为了加速运算而引入了内联缓存,为了提升对象的属性访问速度而引入了隐藏类。
隐藏类是 V8 引擎在运行时自动生成和管理的数据结构,用于跟踪对象的属性和方法,相当于提前定义好对象的形状,以便于提高操作对象的效率。
# 原因
- 当 JavaScript 运行时,例如查找对象上的某一个属性,V8 引擎会通过快慢属性去查找,整个过程非常耗时,因为 V8 在使用一个对象时,并不知道对象的具体形状(属性方法等)
- 而 C 在声明一个对象前就需要定义该对象的结构,C 代码执行前是需要被编译的,编译时对象的结构就已经固定,也就是当代码执行时,对象的形状是无法改变
- 所以 V8 引入了隐藏类的概念,用于跟踪对象的属性和方法以此在内存中快速查找对象属性
# 介绍
隐藏类就是把 JavaScript 的对象也进行静态化, 我们假设这个对象不会删除和新增 ,这样形状就固定了
满足条件之后 V8 就会创建隐藏类,在这个隐藏类会创建对象的基础属性
在 V8 引擎中,每个隐藏类都有一个编号( map id ),用于唯一标识该隐藏类
举个例子,假设我们有以下两个对象:
let obj1 = { name: 1, age: 2 }; | |
let obj2 = { name: 1, age: 2, address: 3 }; |
这两个对象具有相同的形状,即都有属性 name 和 age ,但 obj2 还额外有一个属性 address 。V8 会为它们生成两个不同的隐藏类
// 隐藏类1:包含属性name和age | |
HiddenClass_1 | |
├── map_id: 1 | |
├── property_names: ['name', 'age'] | |
├── transitions: {} | |
└── prototype: Object.prototype | |
// 隐藏类2:包含属性name、age和address | |
HiddenClass_2 | |
├── map_id: 2 | |
├── property_names: ['name', 'age', 'address'] | |
├── transitions: | |
│ ├── a: HiddenClass_1 | |
│ ├── b: HiddenClass_1 | |
│ └── c: null | |
└── prototype: Object.prototype |
可以看到,隐藏类 1 包含属性 name 和 age ,没有过渡表;而隐藏类 2 包含属性 name 、 age 和 address ,其中属性 name 和 age 的过渡表指向隐藏类 1,属性 address 没有过渡表,表示该属性是新添加的
如果两个对象属性一样呢?
如果两个对象具有相同的属性,它们将共享同一个隐藏类。具体来说,当两个对象的属性顺序和类型都相同时,V8 会为它们生成一个共享的隐藏类。
举个例子,假设我们有以下两个对象:
let obj1 = { name: 1, age: 2 }; | |
let obj2 = { name: 1, age: 2 }; |
这两个对象具有相同的形状,即都有属性 name 和 age ,且属性的顺序和类型完全一致。V8 会为它们生成一个共享的隐藏类,如下所示:
HiddenClass_1 | |
├── map_id: 1 | |
├── property_names: ['name', 'age'] | |
├── transitions: {} | |
└── prototype: Object.prototype |
可以看到,隐藏类 1 包含属性 name 和 age ,没有过渡表,而且两个对象都 共享 这个隐藏类。
这种共享隐藏类的机制可以节省内存空间,因为不同的对象可以共享相同的隐藏类结构。
# v8 引擎垃圾回收
首先垃圾回收机制是对于
引用数据类型而言的,普通数据类型由于不知道后续是否会引用某个变量导致不能轻易将变量进行销毁
# 标记清除法
标记清除法是目前在 JS 引擎中最常用的算法,该算法分为
标记和清除两个阶段,标记阶段将所有活动对象做上标记,默认标记为 0, 清除阶段将没有标记的活动对象进行清除,也就是销毁掉标记为 0 的对象。
- 优点:实现简单
- 缺点:清除之后由于剩余对象的内存位置不变,就会出现
内存碎片,这时候为了分配到合适的位置就要进行内存利用的算法判断,导致分配效率慢。
# 引用计数法
引用计数法的策略是跟踪每个对象被使用的次数,当对象被其他变量引用时,它的
引用次数就会加1, 引用次数为 0 就表示没有变量在使用它,就可以将其清除。
- 优点:清晰,并且可以立即回收垃圾。
- 缺点:需要一个计数器,同时计数器需要占很大的位置,因为
引用数量的上限可能会很大,同时最重要的是无法解决循环引用而无法回收的问题。
# 分代式垃圾回收
V8 中将堆内存分为新生代和老生代两区域,采用不同的策略管理垃圾回收
新生代的对象为存活时间较短的对象,简单来说就是新产生的对象,通常只支持 1~8M 的容量,而老生代的对象为存活事件较长或常驻内存的对象,简单来说就是经历过新生代垃圾回收后还存活下来的对象,容量通常比较大
# 新生代
新生代堆内存一分为二:
使用区和空闲区,新加入的对象就会放在使用区,当使用区快写满时,就开始进行垃圾回收,新生代垃圾回收器会对使用区中的活动对象做标记,标记完成之后将使用区的 活动对象 复制进空闲区并进行排序,随后进入垃圾清理阶段,即将非活动对象占用的空间清理掉。最后进行角色互换,把原来的使用区变成空闲区,把原来的空闲区变成使用区。当一个对象经过多次复制后依然存活,它将会被认为是生命周期较长的对象,随后会被移动到老生代中,采用老生代的垃圾回收策略进行管理
另外还有一种情况,如果复制一个对象到空闲区时,空闲区空间占用超过了 25%,那么这个对象会被直接晋升到老生代空间中
新生代采用复制方式的原因是因为:新生代中的大多数对象都是很快变为垃圾 (需要进行清除), 如果直接原地清除就要频繁清理对象,只复制活动对象到空闲区之后就可以直接清除整个使用区,提高了清除效率。
# 老生代
对于大多数占用空间大、存活时间长的对象会被分配到老生代里,因为老生代中的对象通常比较大,如果再如新生代一般分区然后复制来复制去就会非常耗时,从而导致回收执行效率不高,所以老生代垃圾回收器来管理其垃圾回收执行,它的整个流程就采用的就是
标记清除法了
而标记清除法造成的内存碎片问题采用标记整理算法进行优化.
# 总结
分代式机制把一些新、小、存活时间短的对象作为新生代,采用一小块内存频率较高的快速清理,而一些大、老、存活时间长的对象作为老生代,使其很少接受检查,
新老生代的回收机制及频率是不同的,可以说此机制的出现很大程度提高了垃圾回收机制的效率
# 并行回收
新生代对象空间采用并行策略,在执行垃圾回收时,会启动多个线程来负责垃圾清理,以此增加效率。
并行和并发:并发是:一个处理器同时处理多个任务 (并发是逻辑上同时发生), 并行是:多个处理器同时处理多个不同任务 (并行是物理上同时发生)。
# V8 笔记
一、背景
V8 是一个由 Google 开发的开源 JavaScript 引擎,用于 Google Chrome 及 Chromium 中,Node 底层也使用了 V8 引擎。据 BrowerStack 统计,Chrome 的市场占有率将近 62%,而 Node 更是前端工程化以及扩展边界的核心支柱,V8 引擎对于一个前端开发工程师来说重要程度可想而知。
二、V8 引擎是什么
在学习什么是 v8 引擎之前我们需要知道什么是 js 引擎:
JavaScript 引擎是用于执行 JavaScript 代码的程序。它的主要功能是将 JavaScript 代码转换为机器可以理解和执行的低级指令。负责以下任务:
- 解析:将源代码解析为抽象语法树(AST)。
- 编译 / 解释:将 AST 转换为可执行的机器码或字节码。
- 执行:运行生成的代码,并处理内存管理、垃圾回收等。
大家都知道 JS 是解释型语言,由引擎直接读取源码,一边编译一边执行,这样效率相对较低,而编译型语言(如 c++)是把源码直接编译成可直接执行的代码,执行效率更高。
随着技术发展对 JS 的性能要求也越来越高,这就需要更快速的解析和执行 JS 代码,于是产生了 V8 引擎。
V8 是由 Google 开发的开源高性能 JavaScript 和 WebAssembly 引擎,最初用于 Chrome 浏览器,现在也被 Node.js 等项目采用。
V8 的主要特点包括: - 高性能:通过即时编译(JIT)技术,将 JavaScript 编译为本地机器码。
- 内存管理:高效的垃圾回收机制,优化内存使用。
- 支持最新标准:积极实现最新的 ECMAScript 特性。
V8 执行 js 代码的过程: - 第一步,将 js 源代码转化成 AST(抽象语法树)。
- 第二步,通过 Ignition 解释器将 AST 编译成字节码,开始逐句对字节码进行解释成二进制代码并执行。
- 第三步,在解释执行的过程中,标记重复执行的热点代码,将标记的代码通过 Turbofan 引擎进行编译生成效率更高二进制代码,再次运行到这个函数时便只执行高效代码而不再解释执行字节码。
下图简单展示了 V8 的底层架构和执行过程
[图片]
三、V8 引擎的架构
V8 的底层架构主要有三个核心模块(Parse、Ignition、TurboFan)
- Parser 解析器
将 JavaScript 代码转换成 AST(抽象语法树)。该过程主要对 JavaScript 源代码进行词法分析和语法分析;
- 词法分析:对代码中的每一个词或符号进行解析,最终会生成很多 tokens(一个数组,里面包含很多对象);
比如,对 const name = 'curry' 这一行代码进行词法分析:
// 首先对 const 进行解析,因为 const 为一个关键字,所以类型会被记为一个关键词,值为 const
tokens: [
{ type: 'keyword', value: 'const' }
]
// 接着对 name 进行解析,因为 name 为一个标识符,所以类型会被记为一个标识符,值为 name
tokens: [
{ type: 'keyword', value: 'const' },
{ type: 'identifier', value: 'name' }
]
// 以此类推... - 语法分析:在词法分析的基础上,拿到 tokens 中的一个个对象,根据它们不同的类型再进一步分析具体语法,最终生成 AST;
- Ignition 解释器
Ignition 解释器负责将 AST 转换成字节码(Bytecode)并执行。字节码是介于 AST 和机器码之间的一种代码,与特定类型的机器代码无关,需要通过解释器转换成机器码才可以执行。这里有使用字节码的原因以及 V8 引擎的演变过程 V8 引擎的演变以及使用字节码的原因 。
AST 需要先通过字节码生成器,再经过一系列的优化之后才能生成字节码。 其中的优化包括:
Register Optimizer:主要是避免寄存器不必要的加载和存储
Peephole Optimizer:寻找字节码中可以复用的部分,并进行合并
Dead-code Elimination: 删除无用的代码,减少字节码的大小
Ignition 解释器在执行字节码的过程中,会监视代码的执行情况并记录执行信息,如函数的执行次数、每次执行函数时所传的参数等。被执行多次的同一段代码,会被标记成热点代码,交给 TurboFan 编译器进行处理。 - TurboFan 优化编译器
TurboFan 编译器拿到 Ignition 解释器标记的热点代码后,会先优先将优化后字节码编译成更高效的机器码存储起来。下次再次执行相同代码时,会直接执行相应的机器码,大大提升了代码的执行效率。即编译执行。
当一段代码不再是热点代码后,TurboFan 会将优化编译后的机器码还原成字节码,将代码的执行权利交还给 Ignition 解释器。即解释执行。这就是优化回滚。
解释执行启动速度快,执行速度慢,而编译执行启动速度慢,执行速度快。这种将字节码与解释器(解释执行)和编译器(编译执行)结合的混合技术,就是通常所说的即时编译 (JIT)。
中间表示 (IR)
TurboFan 的核心优化过程是基于一种叫做 中间表示 (Intermediate Representation, IR) 的结构化语言。IR 是一种介于高级语言(JavaScript)和低级机器码之间的表示方式,适合进行各种编译优化。TurboFan 将 JavaScript 代码先转化为 IR,并对 IR 进行多轮优化。
TurboFan 的 IR 分为不同的层次:
初始层次的 IR:直接从 JavaScript 源代码转换而来,是一种基础的表示方式。
更高层次的 IR:在初步 IR 的基础上,通过分析和优化生成更复杂的表示,适合进行各种高级的优化。
优化编译过程中的一些优化技术:
- 内联缓存(Inline Caching, IC)
当 V8 首次访问对象的某个属性时,需要查找属性的位置和类型。这个过程比较耗时,因为需要遍历对象的原型链。V8 将属性访问的结果(如属性的位置、类型)缓存起来,形成内联缓存。下次访问时,直接使用缓存的信息,跳过查找过程。这是一个预测变量和表达式的类型的过程,所以如果我们的某个属性变化了类型,就需要重新进行遍历查找,此时代码的执行效率就会变低。 - 函数内联
将被调用的函数代码直接插入调用点,消除函数调用的开销。
在 foo 函数中调用了函数 add,add 函数接收 a,b 两个参数,返回他们的和。如果不经过编译器优化,则会分别生成这两个函数所对应的机器码。
function add(a, b) {
return a + b
}
function foo() {
return add(2, 4)
}
// 优化后
function fooAddInlined () {
const a = 2
const b = 4
return a + b
}
// 因为 fooAddInlined 中 a 和 b 是确定值 还会进一步优化
function fooAddInlined () {
return 6
}
// 递归函数通常不会内联
function factorial (n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
// 递归函数会在其执行过程中多次调用自身,这会导致无限嵌套,内联时如果每次调用都展开,最终会导致代码无限膨胀。因此,递归函数通常不会被内联。
// 还有动态类型函数,具有异常处理的函数这些一般都不会被 v8 优化函数内链
- 逃逸分析:
逃逸分析
逃逸分析就是分析对象的生命周期是否仅限于当前函数,是则被认为是 “未逃逸” 的。如果编译器能够证明一个对象不会 “逃逸” 出某个作用域(例如函数或线程),就可以对其进行优化,例如栈上分配或标量替换,从而减少内存分配和垃圾回收的开销。
未逃逸对象:对未逃逸的对象进行栈上分配,函数执行完毕后自动释放,无需垃圾回收。或进行标量替换,将未逃逸对象的字段替换为独立的局部变量,甚至可能直接在寄存器中操作,消除对象的创建。
逃逸对象:正常进行堆内存分配。
// 逃逸对象
function createEscapingObject () {
const obj = { value: 42 };
return obj;
}
const myObj = createEscapingObject();
console.log(myObj.value);
// 未逃逸对象
function createNonEscapingObject () {
const obj = { value: 42 };
return obj.value + 1;
}
const result = createNonEscapingObject();
console.log(result);
//v8 如何优化
function add (a, b){
const obj = { x: a, y: b }
return obj.x + obj.y
}
// 优化后
function add (a, b){
const obj_x = a
const obj_y = b
return obj_x + obj_y
}
- 常量折叠:在编译期计算常量表达式的结果。
- 死代码消除:移除不会被执行的代码,提高执行效率。
- 隐藏类:为对象创建隐藏类,表示其属性结构。对象共享相同的隐藏类,可以加速属性访问和方法调用。
隐藏类的工作原理:
首先,JavaScript 是一种动态类型语言,对象的属性可以在运行时动态添加、删除或修改。这种动态性给引擎的优化带来了挑战。每次访问对象属性时,解释器需要查找属性名,这涉及遍历原型链,增加了执行时间。
V8 给出的解决方案是为对象创建隐藏类,将 js 中的对象静态化,也就是 v8 在运行 js 的过程中,假设 js 中的对象是静态的,此时可以直接通过偏移量查询来查询对象的属性值(like c++)
隐藏类将对象划分成不同的组,对于组内对象拥有相同的属性名和属性值的情况,将这些组的属性名和对应的偏移位置保存在一个隐藏类中,组内所有对象共享该信息。同时,也可以识别属性不同的对象。
[图片]
[图片]
上图使用 Point 构造了两个对象 p 和 q,这两个对象具有相同的属性名,V8 将它们归为同一个组,也就是隐藏类,这些属性在隐藏类中有相同的偏移值,p 和 q 共享这一信息,进行属性访问时,只需根据隐藏类的偏移值即可。由于 JavaScript 是动态类型语言,在执行时可以更改变量的类型,如果上述代码执行之后,执行 q.z=2,那么 p 和 q 将不再被认为是一个组,q 将是一个新的隐藏类。
下面再举一个例子:
// 对象 A
function PointA(x, y) {
this.x = x;
this.y = y;
}
// 对象 B
function PointB(y, x) {
this.y = y;
this.x = x;
}
const pointA = new PointA(1, 2);
const pointB = new PointA(3, 4);
const pointC = new PointB(5, 6);
//pointA 和 pointB:属性添加顺序相同(x 然后 y),共享同一个隐藏类。
//pointC:属性添加顺序为 y 然后 x,与前两个对象的隐藏类不同。
这个例子说明属性添加顺序的重要性,对象的属性添加顺序会影响隐藏类的创建和共享。
四、内存管理和垃圾回收机制
V8 引擎初始化内存空间主要将堆内存分为以下几个区域:
年轻分代:为新创建的对象分配内存空间,经常需要进行垃圾回收。为方便年轻分代中的内容回收,可再将年轻分代分为两半,一半用来分配,另一半在回收时负责将之前还需要保留的对象复制过来。(from to 空间)
年老分代 : 根据需要将年老的对象、指针、代码等数据保存起来,较少地进行垃圾回收。
大对象:为那些需要使用较多内存对象分配内存,当然同样可能包含数据和代码等分配的内存,一个页面只分配一个对象。
垃圾回收机制:
V8 的垃圾回收机制主要是建立在代际假说(大部分对象在被创建后会很快变得不再使用,而那些存活较长时间的对象,通常会一直存活下去)的基础上,V8 把堆分为新生代和老生带两个区域,同时是设计了两个垃圾回收器(主,副回收器)分别负责新生代和年老代的垃圾回收。
在年轻分代的内存区有 from-space 和 to-space 两个部分,这两个部分都有工作状态和空闲状态,但是一个处于工作状态的时候另一个一定是空闲状态,
假设我们新建了一个对象 obj,这时会去内存堆中的新生代分配,假设此时的 from 是工作状态,那么就会分配在这个区域中,经过一段时间程序的运行,from-space 内存会逐渐达到存储上限,那么此时 V8 引擎会执行一次垃圾清理操作,将 from 区域中的没有使用的对象标记,将未被标记的对象进行复制,置换到 to-space 中有序的重新排列,然后将 from 区域清空,from- space 标记为空闲,to-space 标记为工作。
[图片]
随着程序 deigning 某些对象会一直被使用,但由于我们的年轻分代的存储空间并不大,为了解决这个问题,V8 会让一些对象从新生代存储区晋升到年老内存区存储,从而释放空间,而能成功晋升的对象一定是满足以下条件的:
- 对象经历过一次 Scavenge 算法且未被标记清除;
- 被复制的对象大于 to-space 空间的 25%;
进入到老生代后,就是主垃圾回收器来负责回收,主垃圾回收器会使用标记清除的算法进行垃圾回收。如图所示:
[图片]
被标记的数据会被清除或整理,进行垃圾回收。
五、基于 V8 引擎原理对于优化代码的建议
在上面的介绍中,我们大概了解了 v8 引擎的编译原理,我们知道 TurboFan 会在代码转为机械码的时候进行优化工作,但是有时它自动优化工作并不一定合适(逆优化),所以我们需要在代码层面做的优化尽量满足它的优化条件,按照他的期望代码去进行写。以下是一些建议。 - 根据 V8 的隐藏类优化:尽量保持对象的形状一致,属性初始化顺序一致,避免删除或添加属性。建议在创建对象的时候初始化好所有需要的属性
// 不一致的属性初始化顺序 以下两个函数的属性添加顺序不同,所以 v8 会为其创建不同的隐藏类,无法共享优化
function createPerson1 () {
const person = {};
person.age = 30;
person.name = 'Alice';
return person;
}
function createPerson2() {
const person = {};
person.name = 'Bob';
person.age = 25;
return person;
}
// 优化后一致的属性初始化顺序
function createPersonOptimized1 () {
const person = {};
person.name = 'Alice';
person.age = 30;
return person;
}
function createPersonOptimized2() {
const person = {};
person.name = 'Bob';
person.age = 25;
return person;
}
// 测试两种方式在大量创建对象和访问属性时的性能
// 原始代码的测试函数
function testOriginal () {
const persons = [];
for (let i = 0; i < 1000000; i++) {
const person = i % 2 === 0 ? createPerson1() : createPerson2();
persons.push(person);
}
return persons;
}
// 优化代码的测试函数
function testOptimized () {
const persons = [];
for (let i = 0; i < 1000000; i++) {
const person = i % 2 === 0 ? createPersonOptimized1() : createPersonOptimized2();
persons.push(person);
}
return persons;
}
// 测量函数
function measure (fn) {
const start = performance.now();
fn();
const end = performance.now();
return end - start;
}
// 运行测试
const timeOriginal = measure (testOriginal);
console.log( 原始代码耗时:${timeOriginal.toFixed(2)} );
const timeOptimized = measure(testOptimized);
console.log( 优化代码耗时:${timeOptimized.toFixed(2)} );
// 测试结果:原始代码耗时: 43.98 ms 优化代码耗时: 36.65 ms
// 不要动态添加属性或删除属性,这种操作对性能影响很大,建议在创建对象的时候初始化好所有需要的属性。
// 动态添加属性
const point1 = new Point (1, 2);
point1.z = 3;
const point2 = new Point(4, 5);
point2.w = 6;
// 优化后的代码
function PointOptimized (x, y, z, w) {
this.x = x;
this.y = y;
this.z = z || 0;
this.w = w || 0;
}
const point1Optimized = new PointOptimized(1, 2, 3, 0);
const point2Optimized = new PointOptimized(4, 5, 0, 6);
// 测试对象数量
const iterations = 1000000;
// 未优化的测试函数
function testUnoptimized () {
console.time (' 未优化的代码耗时 ');
const points = [];
for (let i = 0; i < iterations; i++) {
const point = new Point(i, i);
point[ prop${i} ] = i; // 动态添加属性,隐藏类不同
points.push (point);
}
console.timeEnd (' 未优化的代码耗时 ');
}
// 优化后的测试函数
function testOptimized () {
console.time (' 优化后的代码耗时 ');
const points = [];
for (let i = 0; i < iterations; i++) {
const point = new PointOptimized (i, i, 0, 0); // 一次性初始化所有属性
points.push (point);
}
console.timeEnd (' 优化后的代码耗时 ');
}
// 运行测试
testUnoptimized (); //649.262ms
testOptimized();// 38.544ms
// point[ prop${i} ] = i; // 动态添加属性,隐藏类不同,每次都不同,导致创建大量隐藏类,严重影响性能。
// 还有字符串的拼接问题也会影响性能
- 对热点代码函数的优化:保持函数的单态性,确保函数每次调用时的参数类型相同。
对以下代码
function add (x,y){
return x+y;
}
console.log(add(1,2));
console.log(add("hello ","world"));
// 设置迭代次数
const iterations = 10000000; // 一千万次
// 多态函数
function add (a, b) {
return a + b;
}
// 单态函数(数字相加)
function addNumbers(a, b) {
return a + b;
}
// 单态函数(字符串连接)
function concatenateStrings(a, b) {
return a + b;
}
// 性能测试函数
function testPerformance (fn, argsList, label) {
console.time(label);
for (let i = 0; i < iterations; i++) {
const args = argsList[i % argsList.length];
fn(args[0], args[1]);
}
console.timeEnd(label);
}
// 测试多态函数
const polyArgs = [
[1, 2],
['Hello, ', 'World!'],
[3, ' apples'],
];
testPerformance (add, polyArgs, ' 多态函数耗时 ');
// 多态函数耗时: 77.291ms
// 测试单态函数(数字)
const monoNumberArgs = [
[1, 2],
[3, 4],
[5, 6],
];
testPerformance (addNumbers, monoNumberArgs, ' 单态函数(数字)耗时 ');
// 单态函数(数字)耗时: 49.514ms
add () 是多态的,对于数值是数学加法运算,对于字符串是拼接操作,字符串和数值的加法则是先把数值转换为字符串,再做拼接操作。“灵活” 也意味着效率不高,因为要事先判断数据类型、越界检测等等... “投机” 的本质还是程序部性原则,Turbofan 针对 add (1,2) 优化时,它笃定你的 add () 只用于整数加法运行,把其编译为本地机器码的加法运算,去掉了各种不必要的判断。针对 add ("hello","world") 优化时,把其编译为字符串的拼接操作。 add () 的多态方便了开发者,减少了代码量,但如果 add () 毫无规律地在不同操作数之间使用,会导致优化效果很差,所以 Turbofan 不希望程序行为变化。
// 不推荐
function process (value) {
if (typeof value === 'string') {
// 处理字符串
} else if (typeof value === 'number') {
// 处理数字
}
}
// 推荐
function processString (value) {
// 处理字符串
}
function processNumber(value) {
// 处理数字
}
- 对数组优化:
V8 引擎内部根据数组的结构和元素类型,对数组进行不同的优化策略。主要有以下两种类型的数组:
快数组(Fast Elements):
密集数组(Packed Elements):索引从 0 开始,连续且没有空洞的数组。
有洞数组(Holely Elements):存在空洞的数组,但仍以连续的整数索引为主。
慢数组(Dictionary Elements):当数组被认为是稀疏的,或者包含非整数索引时,V8 会将其转换为字典模式,使用哈希表存储,性能较差。
避免键不是递增数字的稀疏数组,使用密集数组。
// 不推荐
const arr = [];
arr [1000] = 'value'; // 创建了一个稀疏数组
// 不推荐
const arr = [1, , 3]; //arr [1] 是一个空洞
// 推荐
const arr = [1, 2, 3];
小心使用 Array.prototype.concat
原因:concat 方法会创建一个新数组,可能会占用大量内存。
替代方案:使用 push 方法和扩展运算符:
const arr1 = [1, 2, 3];
const arr2 = [4, 5, 6];
// 不推荐
const arr3 = arr1.concat (arr2); // 0.039ms
// 推荐
arr1.push (...arr2); // 0.002ms
预分配数组大小:如果知道数组的大小,预先分配可以减少数组动态扩容的开销。
// 示例 1 测试 0.066ms
console.time (' 示例 1');
const size = 1000;
const arr = new Array(size);
for (let i = 0; i < size; i++) {
arr[i] = i;
}
console.timeEnd (' 示例 1');
// 示例 2 测试 0.019ms
console.time (' 示例 2');
const arr1 = new Array(1000);
for (let i = 0; i < 1000; i++) {
arr[i] = i;
}
console.timeEnd (' 示例 2');
避免混合类型的数组,数组中的元素类型不一致,会增加引擎优化的难度。
const arr = [1, 'two', { three: 3 }];
- 避免创建内存泄漏:
及时清理资源:定时器、事件监听器等在不需要时要及时清理。
谨慎使用闭包:避免在闭包中持有不必要的外部引用。
减少全局变量:使用模块化和局部作用域,避免全局命名空间污染。
使用弱引用:在适当情况下,使用 WeakMap、WeakSet 来存储对象的弱引用。
监控和检测:定期使用工具监控内存使用,及时发现和解决内存泄漏问题。 - 循环优化
循环中的代码通常执行次数多,优化循环可以显著提高性能。
将循环中每次迭代都执行但结果不变的计算,移动到循环外部,减少重复计算。
将循环中调用的小函数直接内联到循环内,减少函数调用开销。
在循环中,如果每次迭代都进行属性查找,会导致累积的性能损耗。我们可以将经常访问的对象属性值缓存到局部变量,减少属性查找次数。以下是简单的例子:
// 不推荐 73.355ms
for (let i = 0; i < array.length; i++) {
// 操作
}
// 推荐 38.102ms
for (let i = 0, len = array.length; i < len; i++) {
// 操作
}
在具体实践中的优化,军哥的高斯模糊优化代码的部分用到了这点,将频繁读写变量放到当前作用域进行优化 MiAds 图片裁剪 - 高斯模糊优化
- 利用 V8 的逃逸分析
V8 的逃逸分析可以将未逃逸的对象分配在栈上,减少堆内存分配和垃圾回收的开销。
限制对象的作用域:使对象的作用域局限在函数内部,不要让对象引用逃逸到外部。
// 设置迭代次数
const iterations = 10000000; // 一千万次
// 逃逸对象的测试函数
function testEscaping () {
console.time (' 逃逸对象 ');
for (let i = 0; i < iterations; i++) {
const obj = { value: i };
globalObj = obj; // 模拟对象逃逸
}
console.timeEnd (' 逃逸对象 ');
}
// 未逃逸对象的测试函数
function testNonEscaping () {
console.time (' 未逃逸对象 ');
for (let i = 0; i < iterations; i++) {
const obj = { value: i };
const result = obj.value + 1; // 对象未逃逸
}
console.timeEnd (' 未逃逸对象 ');
}
// 清理全局变量
let globalObj;
// 运行测试
testEscaping (); // 41.403ms
testNonEscaping(); // 5.796ms
// 可以看到几乎差了八倍的性能
- 避免频繁的字符串连接
字符串是不可变的,频繁的字符串连接会创建大量的中间字符串对象,增加内存开销。
// 测试数据
const iterations = 100000;
const items = new Array(iterations).fill('a');
// 低效方法:使用 += 或 使用字符串的 concat 方法
console.time (' 使用 +=');
let result1 = '';
for (let i = 0; i < items.length; i++) {
result1 += items[i];
}
console.timeEnd (' 使用 +=');
// 使用 +=: 5.041ms
// 高效方法:使用数组和 join
console.time (' 使用数组和 join');
const resultArray = [];
for (let i = 0; i < items.length; i++) {
resultArray.push(items[i]);
}
const result2 = resultArray.join('');
console.timeEnd (' 使用数组和 join');
// 使用数组和 join: 1.393ms
每次执行 result += items [i],都会创建一个新的字符串对象,新的字符串长度为 result.length + items [i].length,然后需要将旧的 result 和 items [i] 的内容复制到新的字符串中。
使用数组 push 和 join 的优势是,push 操作只是将字符串引用添加到数组中,没有额外的内存分配。join 方法在连接时会预先计算最终字符串的长度,进行一次性内存分配和复制。
在垃圾回收中,频繁的字符串连接会产生大量的临时字符串对象,增加垃圾回收器的负担。而垃圾回收会暂停应用程序的执行,影响性能。
优化后的方法会减少临时对象的创建,降低垃圾回收的频率和开销。