# Node.js
# 介绍
- Node.js 并不是 JavaScript 应用,也不是编程语言,而是 JavaScript 的运行时。
- Node.js 是构建在 V8 引擎之上的,V8 引擎由 C / C 编写,因此 JavaScript 语言需要编译为 C / C 代码之后才能执行。
- Node.js 采用异步 IO 和事件驱动的设计理念,可以高效的处理大量并发请求,提供了非阻塞 IO 接口和事件循环机制,使其可以编写出高性能、高扩展的应用程序。(异步 IO 通过 libuv 库来实现)
- Node.js 使用 npm 作为包管理工具
- Node.js 适合做一些 IO 密集型应用,不适合做一些 CPU 密集型应用(事件循环机制和异步 IO 使得 Node.js 有很强的处理能力,但是因为 Node.js 单线程的原因,容易造成 CPU 占用率过高)
- 如果非要用 Node.js 做 CPU 密集型应用,需要编写 C++ 插件,或者 Node 提供的 cluster 模块。
# npm
- npm 是 Node.js 的包管理工具,它基于命令行,用于帮助开发者在自己的项目中安装、升级、移除和管理依赖项。
- npm 命令大全
- package.json 配置详解
# npm install
执行 npm install 时,npm 会通过广度优先遍历算法遍历依赖树,npm 会首先处理项目根目录下的依赖,然后逐层处理每个依赖包的依赖,直到所有的依赖被处理完成。在处理每个依赖时,npm 会检查该依赖的版本号是否符合依赖树中其他依赖的版本要求,如果不符合,则会尝试安装适合的版本。
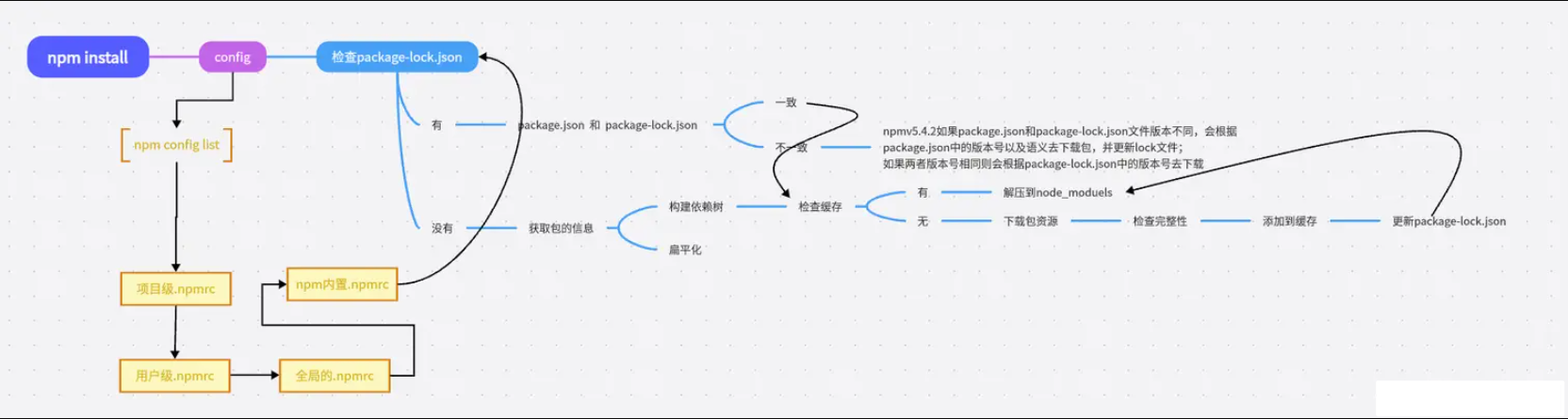
# .npmrc 文件
registry=http://registry.npmjs.org/ | |
# 定义 npm 的 registry,即 npm 的包下载源 | |
proxy=http://proxy.example.com:8080/ | |
# 定义 npm 的代理服务器,用于访问网络 | |
https-proxy=http://proxy.example.com:8080/ | |
# 定义 npm 的 https 代理服务器,用于访问网络 | |
strict-ssl=true | |
# 是否在 SSL 证书验证错误时退出 | |
cafile=/path/to/cafile.pem | |
# 定义自定义 CA 证书文件的路径 | |
user-agent=npm/{npm-version} node/{node-version} {platform} | |
# 自定义请求头中的 User-Agent | |
save=true | |
# 安装包时是否自动保存到 package.json 的 dependencies 中 | |
save-dev=true | |
# 安装包时是否自动保存到 package.json 的 devDependencies 中 | |
save-exact=true | |
# 安装包时是否精确保存版本号 | |
engine-strict=true | |
# 是否在安装时检查依赖的 node 和 npm 版本是否符合要求 | |
scripts-prepend-node-path=true | |
# 是否在运行脚本时自动将 node 的路径添加到 PATH 环境变量中 |
# package-lock.json
文件的作用:
锁定版本号、记录依赖树详细信息
package-lock.json 帮我们做了缓存,他会通过
name + version + integrity信息生成一个唯一的 key,这个 key 能找到对应的 index-v5 下的缓存记录 (npm cache 文件夹下),如果发现有缓存记录,就会找到 tar 包的 hash 值,然后将对应的二进制文件解压到 node_modeules
# npm run
读取 package.json 的 scripts 对应的脚本命令,查找的规则是:
- 当前项目 node_modules/.bin 查找
- 全局 node_modules/.bin 查找
- 环境变量查找
- 找不到,报错
node_modules/.bin 中有三个文件(Node 作为跨平台工具,需要处理平台兼容性)
- .sh 文件是给 Linux unix Macos 使用
- .cmd 给 windows 的 cmd 使用
- .ps1 给 windows 的 powerShell 使用
# npm 生命周期
在 package.json 中的 scripts 字段中,我们可以利用 npm 脚本命名规范使用 npm 的生命周期特性,例如:
"pretest": "node prev.js",
"test": "node index.js",
"posttest": "node post.js"
则执行:npm run test 时,会最先执行 pretest,最后执行 posttest。
# npx
npx 是一个命令行工具,它是 npm 5.2.0 版本中新增的功能。它允许用户在不安装全局包的情况下,运行已安装在本地项目中的包或者远程仓库中的包。
npx 的作用是在命令行中运行 node 包中的可执行文件,而不需要全局安装这些包。这可以使开发人员更轻松地管理包的依赖关系,并且可以避免全局污染的问题。它还可以帮助开发人员在项目中使用不同版本的包,而不会出现版本冲突的问题。
npx 的优势
- 避免全局安装:
npx允许你执行 npm package,而不需要你先全局安装它。 - 总是使用最新版本:如果你没有在本地安装相应的 npm package,
npx会从 npm 的 package 仓库中下载并使用最新版。 - 执行任意 npm 包:
npx不仅可以执行在package.json的scripts部分定义的命令,还可以执行任何 npm package。 - 执行 GitHub gist:
npx甚至可以执行 GitHub gist 或者其他公开的 JavaScript 文件。
npm 和 npx 区别
npx侧重于执行命令的,执行某个模块命令。虽然会自动安装模块,但是重在执行某个命令npm侧重于安装或者卸载某个模块的。重在安装,并不具备执行某个模块的功能。
# npm 私服
优势:
- 可以离线使用,你可以将 npm 私服部署到内网集群,这样离线也可以访问私有的包。
- 提高包的安全性,使用私有的 npm 仓库可以更好的管理你的包,避免在使用公共的 npm 包的时候出现漏洞。
- 提高包的下载速度,使用私有 npm 仓库,你可以将经常使用的 npm 包缓存到本地,从而显著提高包的下载速度,减少依赖包的下载时间。这对于团队内部开发和持续集成、部署等场景非常
搭建:
- 可以克隆 npm 或 cnpm 仓库,更改 yaml 配置文件为自己想要的设置即可
- 使用 verdaccio 工具
npm install verdaccio -gverdaccio- 访问 localhost:4873
- 使用 npm 操作时,加上
--registry http://localhost:4873
# Node 模块化
# CommonJS
支持引入内置模块例如
httposfschild_process等 nodejs 内置模块支持引入第三方模块
expressmd5koa等支持引入自己编写的模块 ./../ 等
支持引入 addon C++ 扩展模块 .node 文件
# ESM
- import 静态导入需要在顶层调用
- import 导入 json 文件需要添加断言(低版本 node 不可用)
- 支持函数式动态导入
# 对比
- CommonJS 基于运行时的同步加载,ESM 基于编译时的异步加载
- CommonJS 是可以修改值的,ESM 值并且不可修改(可读的)
- CommonJS 不可以 tree shaking,ESM 支持 tree shaking
- CommonJS 中顶层的 this 指向这个模块本身,而 ESM 中顶层 this 指向 undefined
# require 执行顺序
- .js 文件,调用 compile 函数进行执行。
- .json 文件,读取文件内容,调用 JSON.parse 方法处理。
- .node 文件,通过 process.dlopen 方法进行处理。
# 全局变量
# global
- 浏览器端的全局对象是 window
- Node 环境的全局对象是 global
- global 上定义的变量在当前环境执行任何文件时都可以访问到
- ES2020 推出 globalThis 用于兼容 window 和 global(自动切换)
# __dirname
当前模块所在目录的绝对路径
# __filename
当前模块文件所在的绝对路径,包括文件名和文件扩展名
# require
# module
# process
process.argv- 第一个参数是当前执行环境的路径
- 第二个参数是当前执行的文件的路径
- 剩余的参数是传递给脚本文件的命令行参数
process.env环境变量process.cwd()返回当前工作目录路径process.on(event,listener),监听进程变化process.exit([code]),退出 Node 进程,提供退出码process.pid返回进程 id
# Buffer 类
Node.js 6.0 版本开始, Buffer 构造函数的使用已被弃用,推荐使用 Buffer.alloc() 、 Buffer.from() 等方法来创建 Buffer 实例。
# DOM、BOM
Node 环境中无法操作 DOM 和 BOM,不过可以借助一些工具进行模拟,例如: jsdom
const fs = require('node:fs') | |
const { JSDOM } = require('jsdom') //jsdom 模拟浏览器环境 | |
const dom = new JSDOM(`<!DOCTYPE html><div id='app'></div>`) | |
const document = dom.window.document; | |
const window = dom.window; | |
fetch('https://api.thecatapi.com/v1/images/search?limit=10&page=1').then(res => res.json()).then(data => { | |
const app = document.getElementById('app') | |
data.forEach(item=>{ | |
const img = document.createElement('img') | |
img.src = item.url | |
img.style.width = '200px' | |
img.style.height = '200px' | |
app.appendChild(img) | |
}) | |
fs.writeFileSync('./index.html', dom.serialize()) | |
}) |
# path 模块
path 模块在 windows 和 posix 系统中是有差异的。
- posix 表示可移植操作系统接口,也就是定义了一套标准,遵守这套标准的操作系统有 (unix,like unix,linux,macOs,windows wsl),用于多个平台间相互兼容
- Windows 并没有完全遵循 POSIX 标准,在 Windows 系统中,路径使用反斜杠(
\)作为路径分隔符。这与 POSIX 系统使用的正斜杠(/)是不同的
差异举例:
path.basename('C:\temp\myfile.html');
// 在posix中 返回: 'C:\temp\myfile.html'
// 在windows中 返回 empmyfile.html
- path.basename 返回文件名(包括后缀)
path.basename('C:/fs/dmq/MI/index.html') // 返回 index.html |
path.extname返回扩展名path.join路径拼接(路径拼接)path.resolve解析绝对路径并且返回绝对路径(路径解析)path.parse将路径解析为对象path.format将对象解析为路径
# os 模块
| API | 作用 | |
|---|---|---|
| 1 | os.type() | 它在 Linux 上返回 'Linux' ,在 macOS 上返回 'Darwin' ,在 Windows 上返回 'Windows_NT' |
| 2 | os.platform() | 返回标识为其编译 Node.js 二进制文件的操作系统平台的字符串。 该值在编译时设置。 可能的值为 'aix' 、 'darwin' 、 'freebsd' 、 'linux' 、 'openbsd' 、 'sunos' 、以及 'win32' |
| 3 | os.release() | 返回操作系统的版本例如 10.xxxx win10 |
| 4 | os.homedir() | 返回用户目录 例如 c:\user\xiaoman 原理就是 windows echo %USERPROFILE% posix $HOME |
| 5 | os.arch() | 返回 cpu 的架构 可能的值为 'arm' 、 'arm64' 、 'ia32' 、 'mips' 、 'mipsel' 、 'ppc' 、 'ppc64' 、 's390' 、 's390x' 、以及 'x64' |
| 6 | os.cups() | 获取 cpu线程 和 cpu 详细信息 |
| 7 | os.networkInterfaces() | 获取 网络信息 |
# process 模块
process.argv- 第一个参数是当前执行环境的路径
- 第二个参数是当前执行的文件的路径
- 剩余的参数是传递给脚本文件的命令行参数
process.env环境变量process.cwd()返回当前工作目录路径process.on(event,listener),监听进程变化process.exit([code]),退出 Node 进程,提供退出码process.pid返回进程 idprocess.arch返回操作系统 CPU 架构process.memoryUsage获取当前进程内存使用情况process.kill(process.pid)用于杀死一个进程
# child_process 模块
子进程是 Nodejs 核心 API,如果你会 shell 命令,他会有非常大的帮助,或者你喜欢编写前端工程化工具之类的,他也有很大的用处,以及处理 CPU 密集型应用。
# 创建子进程
Nodejs 创建子进程共有 7个 API Sync 同步 API ,不加是异步 API
- spawn 执行命令
- exec 执行命令
- execFile 执行可执行文件
- fork 创建 node 子进程
execSync执行命令 同步执行execFileSync执行可执行文件 同步执行spawnSync执行命令 同步执行
# cluster 模块
cluster 模块也用于创建 node 子进程
相比较于 child_process 模块,cluster 模块主要用于利用多核 CPU 的优势,通过创建多个工作进程来提高应用程序的并发处理能力。
cluster 模块创建的每个工作进程都是独立地 node.js 进程,他们共享一个端口和监听器,由主进程负责分配请求到各个工作进程。
cluster 模块自动实现请求的负载均衡,主进程会根据工作进程的负载请情况将请求分配给不同的工作进程。
进程通过 process.send 方法进行通信,但常用于工作进程和主进程之间的通信。
cluster 模块支持优雅关闭工作进程,允许工作进程在关闭之前完成当前正在处理的请求。
# ffmpeg 工具
FFmpeg 是一个开源的跨平台多媒体处理工具,可以用于处理音频、视频和多媒体流。它提供了一组强大的命令行工具和库,可以进行视频转码、视频剪辑、音频提取、音视频合并、流媒体传输等操作。
# events 模块
Node.js 的事件模型采用观察者模式的设计思想,使得双方能够独立地扩展自己。
const EventEmitter = require('events'); | |
const event = new EventEmitter() | |
// 监听 test | |
event.on('test',(data)=>{ | |
console.log(data) | |
}) | |
event.emit('test','data数据') // 派发事件 |
event 实例默认监听 10 个为上限,可以通过 setMaxListeners() 方法来设置监听上限。
event.setMaxListeners(20) |
event.once方法 可以只订阅一次
event.once('test',(data)=>{ | |
console.log('once取代on,只监听一次') | |
}) |
event.off 方法取消订阅
event.on('test', fn) // 订阅事件 | |
event.off('test', fn) // 取消事件订阅 |
# SSE
SSE(server send events)服务端推送事件
是一种实现服务端向客户端推送数据的技术,也被称为事件流
它是基于 HTTP 协议,利用 HTTP 协议长连接的优势,实现服务端向客户端推送实时数据。
浏览器端需要使用
EventSource注册 api 地址,服务端需要对该地址的响应头中设置 Content-Type 为text/event-stream
node 后端:
import express from 'express'; | |
const app = express(); | |
app.get('/api/sse', (req, res) => { | |
res.writeHead(200, { | |
'Content-Type': 'text/event-stream', // 核心返回数据流 | |
'Connection': 'close' | |
}) | |
const data = fs.readFileSync('./index.txt', 'utf8') | |
const total = data.length; | |
let current = 0; | |
//mock sse 数据 | |
let time = setInterval(() => { | |
console.log(current, total) | |
if (current >= total) { | |
console.log('end') | |
clearInterval(time) | |
return | |
} | |
// 返回自定义事件名 | |
res.write(`event:name\n`) | |
// 返回数据 | |
res.write(`data:${data.split('')[current]}\n\n`) | |
current++ | |
}, 300) | |
}) | |
app.listen(3000, () => { | |
console.log('Listening on port 3000'); | |
}); |
客户端:
const sse = new EventSource('http://localhost:3000/api/sse' ) | |
if (sse.readyState === EventSource.CONNECTING) { | |
console.log('正在连接服务器...'); | |
} else if (sse.readyState === EventSource.OPEN) { | |
console.log('已经连接上服务器!'); | |
} else if (sse.readyState === EventSource.CLOSED) { | |
console.log('连接已经关闭。'); | |
} | |
sse.onmessage = (data)=>{ | |
console.log(data); | |
} | |
sse.onerror = (e)=>{ | |
sse.close(); // 关闭连接 | |
console.error(e); | |
} | |
sse.addEventListener('open', (e) => { | |
console.log('连接成功'); | |
}) | |
// 对应后端 nodejs 自定义的事件名 lol | |
sse.addEventListener('name', (e) => { | |
console.log(e.data) | |
}) |
# util 模块
Node.js 内部提供的工具集模块,方便快速开发
util.promisify将函数改为 promise 类型的形式util.callbackify将 promise 类型的 api 改为函数形式util.format用于格式化文本%s:String将用于转换除BigInt、Object和-0之外的所有值。BigInt值将用n表示,没有用户定义的toString函数的对象使用具有选项{ depth: 0, colors: false, compact: 3 }的util.inspect()进行检查。%d:Number将用于转换除BigInt和Symbol之外的所有值。%i:parseInt(value, 10)用于除BigInt和Symbol之外的所有值。%f:parseFloat(value)用于除Symbol之外的所有值。%j: JSON。 如果参数包含循环引用,则替换为字符串'[Circular]'。%o:Object. 具有通用 JavaScript 对象格式的对象的字符串表示形式。 类似于具有选项{ showHidden: true, showProxy: true }的util.inspect()。 这将显示完整的对象,包括不可枚举的属性和代理。%O:Object. 具有通用 JavaScript 对象格式的对象的字符串表示形式。 类似于没有选项的util.inspect()。 这将显示完整的对象,但不包括不可枚举的属性和代理。%c:CSS. 此说明符被忽略,将跳过任何传入的 CSS。%%: 单个百分号 ('%')。 这不消费参数。
其他工具函数省略
# pngquant 工具
pngquant 是一个用于压缩 PNG 图像文件的工具。它可以显著减小 PNG 文件的大小,同时保持图像质量和透明度。通过减小文件大小,可以提高网页加载速度,并节省存储空间。 pngquant 提供命令行接口和库,可轻松集成到各种应用程序和脚本中。
# fs 模块
在 Node.js 中, fs 模块是文件系统模块(File System module)的缩写,它提供了与文件系统进行交互的各种功能。通过 fs 模块,你可以执行诸如读取文件、写入文件、更改文件权限、创建目录等操作, Node.js 核心API之一 。
# 同步与异步
fs 支持同步和异步两种模式 增加了
Syncfs 就会采用同步的方式运行代码,会阻塞下面的代码,不加 Sync 就是异步的模式不会阻塞。fs 新增了 promise 版本,只需要在引入包后面增加 /promise 即可,fs 便可支持 promise 回调。
fs 返回的是一个 buffer 二进制数据 每两个十六进制数字表示一个字节
# api
fs.readFile异步读取文件fs.writeFile异步写入文件fs.appendFile文件异步追加写入内容fs.copyFile文件异步拷贝写入fs.open异步打开文件fs.close异步关闭文件fs.read异步读取文件fs.write异步将 Buffer 中的数据写入文件fs.access异步检查文件是否可读可写fs.stat异步获取文件目录的 stats 对象(文件夹信息)fs.mkdir异步创建文件夹fs.readdir异步读取文件夹fs.rmdir异步删除目录fs.unlink异步删除文件- 以上方法都有对应的同步执行的方法,在方法名后面加上 Sync 后缀即可。
# fs/promises
node 中 fs 模块的方法提供了 Promise 版本的调用形式,导入即可使用 promise 的使用方式调用 api
# 源码
Node.js 中 fs 模块是由 libuv 来进行调度的,文件读取完成之后 libuv 才会将 fs 的结果推入 V8 的队列。
# writeFileSync
- 第一个参数是要写入的文件
- 第二个参数是写入的内容
- 第三个参数是写入方式配置项,其 flag 有以下配置:
'a': 打开文件进行追加。 如果文件不存在,则创建该文件。'ax': 类似于'a'但如果路径存在则失败。'a+': 打开文件进行读取和追加。 如果文件不存在,则创建该文件。'ax+': 类似于'a+'但如果路径存在则失败。'as': 以同步模式打开文件进行追加。 如果文件不存在,则创建该文件。'as+': 以同步模式打开文件进行读取和追加。 如果文件不存在,则创建该文件。'r': 打开文件进行读取。 如果文件不存在,则会发生异常。'r+': 打开文件进行读写。 如果文件不存在,则会发生异常。'rs+': 以同步模式打开文件进行读写。 指示操作系统绕过本地文件系统缓存。'w': 打开文件进行写入。 创建(如果它不存在)或截断(如果它存在)该文件。'wx': 类似于'w'但如果路径存在则失败。'w+': 打开文件进行读写。 创建(如果它不存在)或截断(如果它存在)该文件。'wx+': 类似于'w+'但如果路径存在则失败。
例如追加文件内容除了可以使用 appendFileSync 之外,还可以:
fs.writeFileSync('index.txt', '追加的内容',{ | |
flag: 'a' // 配置 options 中的 flag | |
}) |
# 可写流
const fs = require('node:fs') | |
let verse = [ | |
'待到秋来九月八', | |
'我花开后百花杀', | |
'冲天香阵透长安', | |
'满城尽带黄金甲' | |
] | |
let writeStream = fs.createWriteStream('index.txt') // 创建写入流 | |
verse.forEach(item => { | |
writeStream.write(item + '\n') // 写入内容 | |
}) | |
writeStream.end() | |
writeStream.on('finish',()=>{ // 监听写入完成事件 | |
console.log('写入完成') | |
}) |
我们可以创建一个可写流 打开一个通道,可以一直写入数据,用于处理大量的数据写入,写入完成之后调用 end 关闭可写流,监听 finish 事件 写入完成
# 硬链接、软连接
# inode
- 文件存储在磁盘上,磁盘的最小存储单位叫做
扇区,每个扇区存储 512 字节 - 操作系统读取磁盘时,不会一个扇区一个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,多个扇区称之为
块 块是文件读取的最小单位- 文件数据都存储在
块中,因此需要一个地方存储文件的元信息,这中存储文件元信息的区域就叫做inode,索引节点 - 创建软链接时生成了新的
inode,创建硬链接时没有。
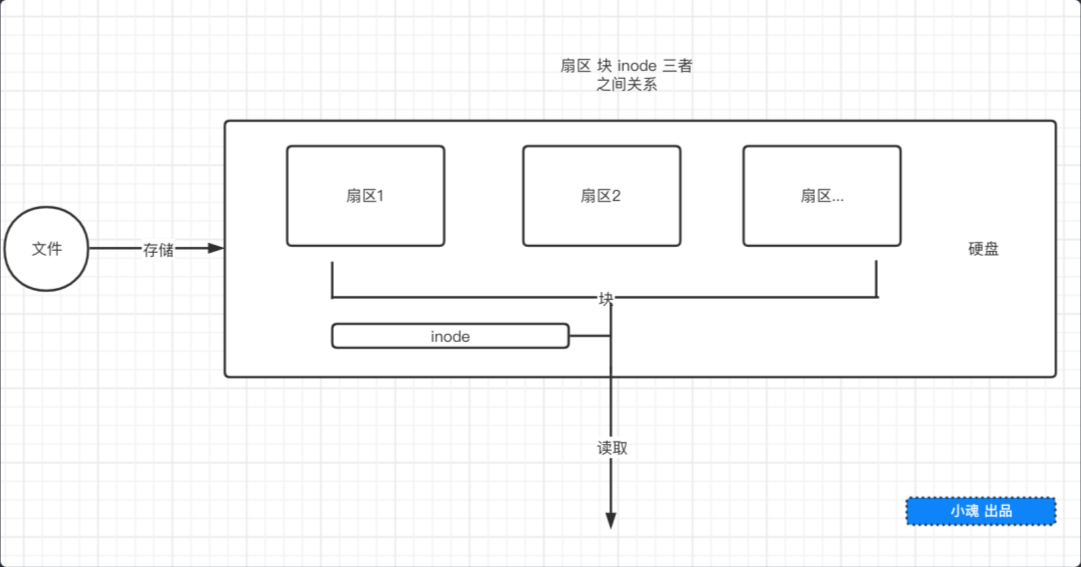
inode 中包含信息:
- 文件的字节数
- 文件拥有者 ID
- 文件的 Group ID
- 文件读、写、执行权限
- 文件的时间戳
- 链接数
- 文件数据 block 的位置
每一个 inode 都有一个唯一的标识码 ,上面的输出信息中 ino 就是 inode 的唯一标识码,在 linux 系统内部使用 inode 的标识码来识别文件,并不使用文件名。之前系的
在 linux 系统中,目录也是一种文件。目录文件包含一系列目录项,每一个目录项由两部分组成:所包含文件的文件名,以及文件名对应的 inode 标识码。我们可以使用 ls -i 来列出目录中的文件以及所有的 inde 标识码。这里也可以解释可能小伙伴们觉得说不通的问题,仅修改目录的读权限,并不能实现读取目录下所有文件内容的原因,最后需要通过递归目录下的文件来进行修改。
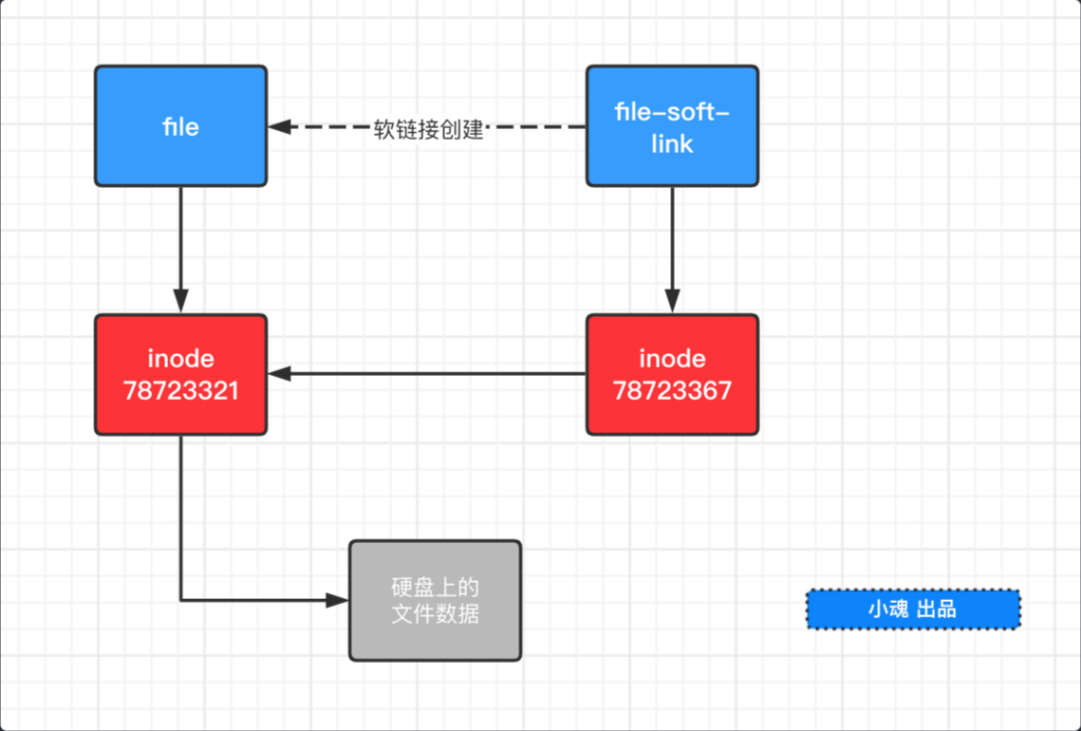
# 软链接
软链接类似于 Window 中的 “快捷方式” 。创建软链接会创建一个新的 inode ,比如为文件 a 创建了软链接文件 b,文件 b 内部会指向 a 的 inode 。当我们读取文件 b 的时候,系统会自动导向文件 a ,文件 b 就是文件 a 软连接 (或者叫符号链接)。
- 访问:创建了软链接后我们就可以使用不同的文件名访问相同的内容,
- 修改:修改文件
a的内容,文件b的内容也会发生改变,对文件内容的修改向放映到所有文件。 - 删除:当我们删除源文件
a时,在访问软连接文件 b 是,会报错"No such file or directory"
可以直接使用 linux 命令 ln -s source target 来创建软链接 (注意:表示 target “指向” source )
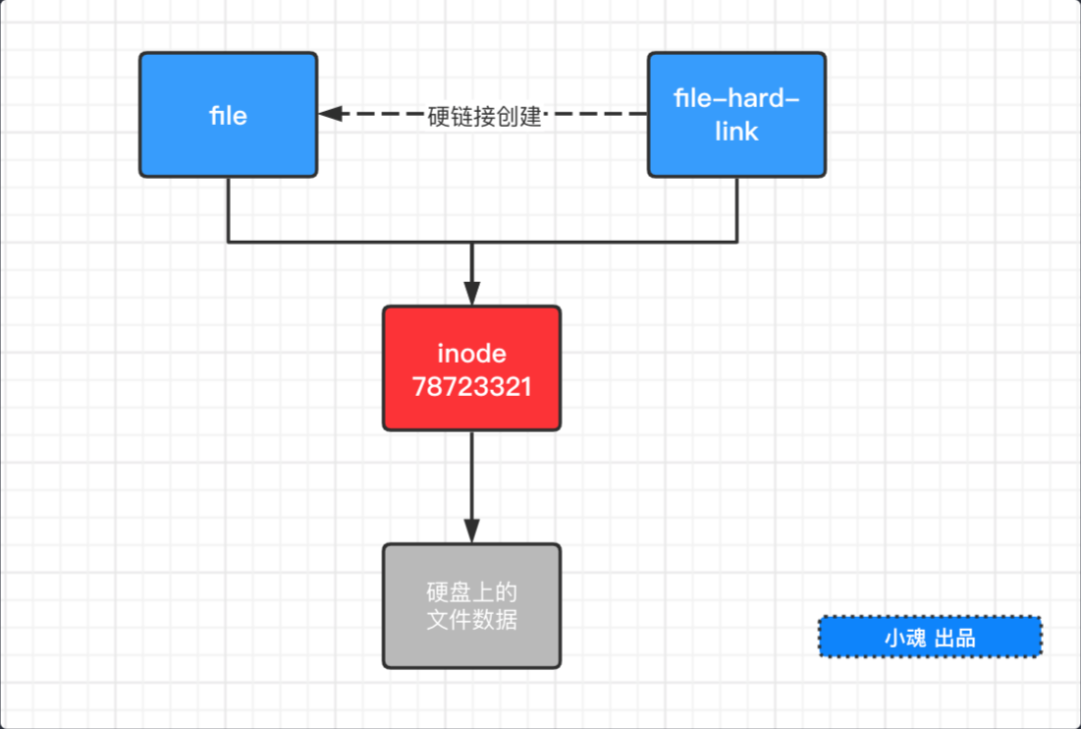
# 硬链接
一般情况,一个文件名 "唯一" 对应一个 inode 。但是 linux 允许多个文件名都指向同一个 inode 。表示我们可以使用不同对文件名访问同样的内容;对文件内容进行修改将放映到所有文件;删除一个文件不影响另一个文件对访问。这种机制就被称为 "硬链接"
硬链接的创建 可以直接使用 linux 命令 ln source target 来创建硬链接(注意: source 已存在的文件,target 是将要建立的链接)
# 创建链接
fs.linkSync('./index.txt', './index2.txt') // 硬链接 | |
fs.symlinkSync('./index.txt', './index3.txt' ,"file") // 软连接 |
# 用途
硬链接的作用和用途如下:
- 文件共享:硬链接允许多个文件名指向同一个文件,这样可以在不同的位置使用不同的文件名引用相同的内容。这样的共享文件可以节省存储空间,并且在多个位置对文件的修改会反映在所有引用文件上。
- 文件备份:通过创建硬链接,可以在不复制文件的情况下创建文件的备份。如果原始文件发生更改,备份文件也会自动更新。这样可以节省磁盘空间,并确保备份文件与原始文件保持同步。
- 文件重命名:通过创建硬链接,可以为文件创建一个新的文件名,而无需复制或移动文件。这对于需要更改文件名但保持相同内容和属性的场景非常有用。
软链接的一些特点和用途如下:
- 软链接可以创建指向文件或目录的引用。这使得你可以在不复制或移动文件的情况下引用它们,并在不同位置使用不同的文件名访问相同的内容。
- 软链接可以用于创建快捷方式或别名,使得你可以通过一个简短或易记的路径来访问复杂或深层次的目录结构。
- 软链接可以用于解决文件或目录的位置变化问题。如果目标文件或目录被移动或重命名,只需更新软链接的目标路径即可,而不需要修改引用该文件或目录的其他代码。
# crypto 模块
crypto 模块的目的是为了提供通用的 加密和哈希算法 。用纯 JavaScript 代码实现这些功能不是不可能,但速度会非常慢。nodejs 用 C/C++ 实现这些算法后,通过 crypto 这个模块暴露为 JavaScript 接口,这样用起来方便,运行速度也快。
密码学是计算机科学中的一个重要领域,它涉及到加密、解密、哈希函数和数字签名等技术。Node.js 是一个流行的服务器端 JavaScript 运行环境,它提供了强大的密码学模块,使开发人员能够轻松地在其应用程序中实现各种密码学功能。本文将介绍密码学的基本概念,并探讨 Node.js 中常用的密码学 API。
# 对称加密
js复制代码const crypto = require('node:crypto'); | |
// 生成一个随机的 16 字节的初始化向量 (IV) | |
const iv = Buffer.from(crypto.randomBytes(16)); | |
// 生成一个随机的 32 字节的密钥 | |
const key = crypto.randomBytes(32); | |
// 创建加密实例,使用 AES-256-CBC 算法,提供密钥和初始化向量 | |
const cipher = crypto.createCipheriv("aes-256-cbc", key, iv); | |
// 对输入数据进行加密,并输出加密结果的十六进制表示 | |
cipher.update("小满zs", "utf-8", "hex"); | |
const result = cipher.final("hex"); | |
// 解密 | |
const de = crypto.createDecipheriv("aes-256-cbc", key, iv); | |
de.update(result, "hex"); | |
const decrypted = de.final("utf-8"); | |
console.log("Decrypted:", decrypted); |
对称加密是一种简单而快速的加密方式,它使用相同的密钥(称为对称密钥)来进行加密和解密。这意味着发送者和接收者在加密和解密过程中都使用相同的密钥。对称加密算法的加密速度很快,适合对大量数据进行加密和解密操作。然而,对称密钥的安全性是一个挑战,因为需要确保发送者和接收者都安全地共享密钥,否则有风险被未授权的人获取密钥并解密数据。
# 非对称加密
js复制代码const crypto = require('node:crypto') | |
// 生成 RSA 密钥对 | |
const { privateKey, publicKey } = crypto.generateKeyPairSync('rsa', { | |
modulusLength: 2048, | |
}); | |
// 要加密的数据 | |
const text = '小满zs'; | |
// 使用公钥进行加密 | |
const encrypted = crypto.publicEncrypt(publicKey, Buffer.from(text, 'utf-8')); | |
// 使用私钥进行解密 | |
const decrypted = crypto.privateDecrypt(privateKey, encrypted); | |
console.log(decrypted.toString()); |
非对称加密使用一对密钥,分别是公钥和私钥。发送者使用接收者的公钥进行加密,而接收者使用自己的私钥进行解密。公钥可以自由分享给任何人,而私钥必须保密。非对称加密算法提供了更高的安全性,因为即使公钥泄露,只有持有私钥的接收者才能解密数据。然而,非对称加密算法的加密速度相对较慢,不适合加密大量数据。因此,在实际应用中,通常使用非对称加密来交换对称密钥,然后使用对称加密算法来加密实际的数据。
# 哈希函数
const crypto = require('node:crypto'); | |
// 要计算哈希的数据 | |
let text = '123456'; | |
// 创建哈希对象,并使用 MD5 算法 | |
const hash = crypto.createHash('md5'); | |
// 更新哈希对象的数据 | |
hash.update(text); | |
// 计算哈希值,并以十六进制字符串形式输出 | |
const hashValue = hash.digest('hex'); | |
console.log('Text:', text); | |
console.log('Hash:', hashValue); |
哈希函数具有以下特点:
- 固定长度输出:不论输入数据的大小,哈希函数的输出长度是固定的。例如,常见的哈希函数如 MD5 和 SHA-256 生成的哈希值长度分别为 128 位和 256 位。
- 不可逆性:哈希函数是单向的,意味着从哈希值推导出原始输入数据是非常困难的,几乎不可能。即使输入数据发生微小的变化,其哈希值也会完全不同。
- 唯一性:哈希函数应该具有较低的碰撞概率,即不同的输入数据生成相同的哈希值的可能性应该非常小。这有助于确保哈希值能够唯一地标识输入数据。
使用场景
- 我们可以避免密码明文传输 使用 md5 加密或者 sha256
- 验证文件完整性,读取文件内容生成 md5 如果前端上传的 md5 和后端的读取文件内部的 md5 匹配说明文件是完整的
# md 转 html
# 工具
- ejs:模板渲染库,使用特定语法填充内容,进行模板渲染
- marked:用于将 Markdown 语法转为 HTML
- browserSync:用于在浏览器实时预览和同步刷新
# 使用
index.js
const ejs = require('ejs'); // 导入 ejs 库,用于渲染模板 | |
const fs = require('node:fs'); // 导入 fs 模块,用于文件系统操作 | |
const marked = require('marked'); // 导入 marked 库,用于将 Markdown 转换为 HTML | |
const readme = fs.readFileSync('README.md'); // 读取 README.md 文件的内容,直接 read 的结果是 buffer 中的数据,通过 toString 方法变为原始内容 | |
const browserSync = require('browser-sync'); // 导入 browser-sync 库,用于实时预览和同步浏览器 | |
const openBrowser = () => { | |
// 创建浏览器服务 | |
const browser = browserSync.create() | |
// 初始化浏览器服务 ,传入目录和主页 | |
browser.init({ | |
server: { | |
baseDir: './', | |
index: 'index.html', | |
} | |
}) | |
return browser | |
} | |
//ejs 模板进行渲染,传入变量 | |
ejs.renderFile('template.ejs', { | |
content: marked.parse(readme.toString()), | |
title:'markdown to html' | |
},(err,data)=>{ | |
if(err){ | |
console.log(err) | |
} | |
// 将文件内容写入到 index.html | |
let writeStream = fs.createWriteStream('index.html') | |
writeStream.write(data) | |
writeStream.close() | |
writeStream.on('finish',()=>{ | |
//index.html 写入完毕之后,打开浏览器实时预览 | |
openBrowser() | |
}) | |
}) |
template.ejs
<!DOCTYPE html> | |
<html lang="en"> | |
<head> | |
<meta charset="UTF-8"> | |
<meta name="viewport" content="width=device-width, initial-scale=1.0"> | |
<title><%= title %></title> | |
<link rel="stylesheet" href="./index.css"> <!-- 引入 css 样式 --> | |
</head> | |
<body> | |
<%- content %> | |
</body> | |
</html> |
index.css
/* Markdown 通用样式 */ | |
/* 设置全局字体样式 */ | |
body { | |
font-family: Arial, sans-serif; | |
font-size: 16px; | |
line-height: 1.6; | |
color: #333; | |
} | |
/* 设置标题样式 */ | |
h1,h2,h3,h4,h5,h6 { | |
margin-top: 1.3em; | |
margin-bottom: 0.6em; | |
font-weight: bold; | |
} | |
h1 { | |
font-size: 2.2em; | |
} | |
h2 { | |
font-size: 1.8em; | |
} | |
h3 { | |
font-size: 1.6em; | |
} | |
h4 { | |
font-size: 1.4em; | |
} | |
h5 { | |
font-size: 1.2em; | |
} | |
h6 { | |
font-size: 1em; | |
} | |
/* 设置段落样式 */ | |
p { | |
margin-bottom: 1.3em; | |
} | |
/* 设置链接样式 */ | |
a { | |
color: #337ab7; | |
text-decoration: none; | |
} | |
a:hover { | |
text-decoration: underline; | |
} | |
/* 设置列表样式 */ | |
ul, | |
ol { | |
margin-top: 0; | |
margin-bottom: 1.3em; | |
padding-left: 2em; | |
} | |
/* 设置代码块样式 */ | |
pre { | |
background-color: #f7f7f7; | |
padding: 1em; | |
border-radius: 4px; | |
overflow: auto; | |
} | |
code { | |
font-family: Consolas, Monaco, Courier, monospace; | |
font-size: 0.9em; | |
background-color: #f7f7f7; | |
padding: 0.2em 0.4em; | |
border-radius: 4px; | |
} | |
/* 设置引用样式 */ | |
blockquote { | |
margin: 0; | |
padding-left: 1em; | |
border-left: 4px solid #ddd; | |
color: #777; | |
} | |
/* 设置表格样式 */ | |
table { | |
border-collapse: collapse; | |
width: 100%; | |
margin-bottom: 1.3em; | |
} | |
table th, | |
table td { | |
padding: 0.5em; | |
border: 1px solid #ccc; | |
} | |
/* 添加一些额外的样式,如图片居中显示 */ | |
img { | |
display: block; | |
margin: 0 auto; | |
max-width: 100%; | |
height: auto; | |
} | |
/* 设置代码行号样式 */ | |
pre code .line-numbers { | |
display: inline-block; | |
width: 2em; | |
padding-right: 1em; | |
color: #999; | |
text-align: right; | |
user-select: none; | |
pointer-events: none; | |
border-right: 1px solid #ddd; | |
margin-right: 0.5em; | |
} | |
/* 设置代码行样式 */ | |
pre code .line { | |
display: block; | |
padding-left: 1.5em; | |
} | |
/* 设置代码高亮样式 */ | |
pre code .line.highlighted { | |
background-color: #f7f7f7; | |
} | |
/* 添加一些响应式样式,适应移动设备 */ | |
@media only screen and (max-width: 768px) { | |
body { | |
font-size: 14px; | |
line-height: 1.5; | |
} | |
h1 { | |
font-size: 1.8em; | |
} | |
h2 { | |
font-size: 1.5em; | |
} | |
h3 { | |
font-size: 1.3em; | |
} | |
h4 { | |
font-size: 1.1em; | |
} | |
h5 { | |
font-size: 1em; | |
} | |
h6 { | |
font-size: 0.9em; | |
} | |
table { | |
font-size: 14px; | |
} | |
} |
# zlib 模块
# 介绍
- Node.js 中 zlib 模块用于对数据提供压缩和解压缩的功能,以便在应用程序中减少数据的传输大小、节省带宽和提高性能
- 该模块包含各种压缩算法,包含 Deflate、Gzip 和 Raw Deflate 等
# 作用
数据压缩,减少数据的大小,这在网络传输和磁盘存储中很有用,可以节省带宽和存储空间
数据解压缩
流压缩,zlib 模块支持流式的方式进行数据的压缩和解压缩,使得可以对大型文件或者网络数据流进行逐步处理,而不需要将整个数据加载到内存中。
// 压缩文件(以 Gzip 为例)const zlib = require('zlib')
const fs = require('node:fs')
const readStream = fs.createReadStream('./test.txt');
const writeStream = fs.createWriteStream('./test.txt.gz');
// 将 readStream 利用 zlib 进行压缩,pipe 到下一个管道,最后 pipe 到写入流readStream.pipe(zlib.createGzip()).pipe(writeStream)
// 解压缩文件const reStr = fs.createReadStream('./test.txt.gz');
const wrStr = fs.createWriteStream('./t.txt');
const gunzip = zlib.createGunzip();
reStr.pipe(gunzip).pipe(wrStr);
gunzip.on('error', (err) => {
console.error('Gunzip error:', err);
});
reStr.on('end', () => {
console.log('Input file has been read.');
});
wrStr.on('finish', () => {
console.log('Output file has been written.');
});
# 对比
- 压缩算法:Gzip 使用的是 Deflate 压缩算法,该算法结合了 LZ77 算法和哈夫曼编码。LZ77 算法用于数据的重复字符串的替换和引用,而哈夫曼编码用于进一步压缩数据。
- 压缩效率:Gzip 压缩通常具有更高的压缩率,因为它使用了哈夫曼编码来进一步压缩数据。哈夫曼编码根据字符的出现频率,将较常见的字符用较短的编码表示,从而减小数据的大小。
- 压缩速度:相比于仅使用 Deflate 的方式,Gzip 压缩需要更多的计算和处理时间,因为它还要进行哈夫曼编码的步骤。因此,在压缩速度方面,Deflate 可能比 Gzip 更快。
- 应用场景:Gzip 压缩常用于文件压缩、网络传输和 HTTP 响应的内容编码。它广泛应用于 Web 服务器和浏览器之间的数据传输,以减小文件大小和提高网络传输效率。
- deflate 是一种过时的压缩方式,现代浏览器对其支持并不友好
zlib 模块可以用于对发送网络请求返回的数据进行压缩,节省带宽和传输速率。
# brotli
- 针对常见的 Web 资源内容,Brotli 的性能比 Gzip 提高了 17-25%;
- 当 Brotli 压缩级别为 1 时,压缩率比 Gzip 的最高级别 9 还要高;
- 在处理不同的 HTML 文档时,Brotli 依然能提供非常高的压缩率。
- 除了 IE 和 Opera Mini 之外,几乎所有主流浏览器都已支持 Brotli 算法。
- 尽管 Brotli 在压缩方面表现出色,但随着压缩级别的提高,Brotli 压缩所需的时间也会相应增加。换句话说,Brotli 需要更多的计算能力,这可能意味着更高的设备和软件成本。
- Brotli 要求浏览器必须支持 HTTPS 才能使用。
# http 模块
# 介绍
- http 模块是 Node.js 中用于创建和处理 HTTP 服务器和客户端的核心模块
- http 模块使得基于 HTTP 协议的应用程序更加简单和灵活
- http 模块也可以用于创建代理服务器,用于转发客户端的请求到其他服务器,代理服务器可以用于负载均衡、缓存、安全过滤或跨域请求等场景。通过在代理服务器上添加逻辑,可以对请求和响应进行修改、记录或过滤。
- http 模块也可以创建文件服务器,用于提供静态文件,通过读取文件并将其作为响应发送给客户端。
# 使用
const http = require('http') | |
const httpServer = http.createServer((req,res)=>{ | |
if(req.method === 'POST'){} | |
else if(req.method === 'GET'){} | |
}) | |
httpServer.listen(98,()=>{ | |
console.log('服务器启动,端口:98'); | |
}) |
# url 模块
可以通过 url 模块来解析 req 的请求路径,来进一步精细化响应内容。
const http = require('node:http'); // 引入 http 模块 | |
const url = require('node:url'); // 引入 url 模块 | |
// 创建 HTTP 服务器,并传入回调函数用于处理请求和生成响应 | |
http.createServer((req, res) => { | |
const { pathname, query } = url.parse(req.url, true); // 解析请求的 URL,获取路径和查询参数 | |
if (req.method === 'POST') { // 检查请求方法是否为 POST | |
if (pathname === '/post') { // 检查路径是否为 '/post' | |
let data = ''; | |
req.on('data', (chunk) => { | |
data += chunk; // 获取 POST 请求的数据 | |
console.log(data); | |
}); | |
req.on('end', () => { | |
res.setHeader('Content-Type', 'application/json'); // 设置响应头的 Content-Type 为 'application/json' | |
res.statusCode = 200; // 设置响应状态码为 200 | |
res.end(data); // 将获取到的数据作为响应体返回 | |
}); | |
} else { | |
res.setHeader('Content-Type', 'application/json'); // 设置响应头的 Content-Type 为 'application/json' | |
res.statusCode = 404; // 设置响应状态码为 404 | |
res.end('Not Found'); // 返回 'Not Found' 作为响应体 | |
} | |
} else if (req.method === 'GET') { // 检查请求方法是否为 GET | |
if (pathname === '/get') { // 检查路径是否为 '/get' | |
console.log(query.a); // 打印查询参数中的键名为 'a' 的值 | |
res.end('get success'); // 返回 'get success' 作为响应体 | |
} | |
} | |
}).listen(98, () => { | |
console.log('server is running on port 98'); // 打印服务器启动的信息 | |
}); |
# net 模块
介绍:
- net 模块是 Node.js 的核心模块之一,提供了用于创建基于网络的应用程序的 API
- net 模块主要用于创建 TCP 服务器和 TCP 客户端,以及处理网络通信
应用场景:
服务端之间的通讯
服务端之间的通讯可以直接使用 TCP 通讯,而不需要上升到 http 层
server.js(TCP 层面的服务端)
const net = require('net')
const server = net.createServer((client)=>{
setTimeout(() => {
client.write('发送TCP内容')
}, 1000);
})
server.listen(3000,()=>{
console.log('3000端口启动服务');
})
connection.js(TCP 层面的客户端)
const net = require('net')
const connection = net.createConnection({
host:'127.0.0.1',
port:3000
})
connection.on('data',(data)=>{
console.log(data.toString());
})
从传输层实现 http 协议
const net = require('net');
const html = `<h1>TCP Server</h1>`
const reposneHeader = [
'HTTP/1.1 200 OK',
'Content-Type: text/html',
'Content-Length: ' + html.length,
'Server: Nodejs',
'\r\n',
html
]const http = net.createServer((connect)=>{
connect.on('data',(data)=>{
console.log(data.toString().slice(0,3));
if(data.toString().startsWith('GET')){
connect.write(reposneHeader.join('\r\n')) // 向 TCP 连接中写入 html 响应
connect.end()
}})
})
http.listen(3000,()=>{
console.log('服务启动');
})
# 动静分离
- 动静分离是 Web 服务器架构中常用的优化技术,用于提高网站的性能和可伸缩性
- 原理就是将静态资源的请求和动态内容分开处理(通过 url,例如加上 static 后缀表示静态)
- 好处在于:
- 性能优化(静态资源内容不变,可以利用缓存)
- 负载均衡(动态内容请求分发到不同的服务器或服务上,平衡服务器的负载)
- 安全性(动态内容往往涉及敏感信息,动静分离可以更好地管理访问控制和安全策略)
import http from 'node:http' // 导入 http 模块 | |
import fs from 'node:fs' // 导入文件系统模块 | |
import path from 'node:path' // 导入路径处理模块 | |
import mime from 'mime' // 导入 mime 模块 | |
const server = http.createServer((req, res) => { | |
const { url, method } = req | |
// 处理静态资源 | |
if (method === 'GET' && url.startsWith('/static')) { | |
const filePath = path.join(process.cwd(), url) // 获取文件路径 | |
const mimeType = mime.getType(filePath) // 获取文件的 MIME 类型 | |
console.log(mimeType) // 打印 MIME 类型 | |
fs.readFile(filePath, (err, data) => { // 读取文件内容 | |
if (err) { | |
res.writeHead(404, { | |
"Content-Type": "text/plain" // 设置响应头为纯文本类型 | |
}) | |
res.end('not found') // 返回 404 Not Found | |
} else { | |
res.writeHead(200, { | |
"Content-Type": mimeType, // 设置响应头为对应的 MIME 类型 | |
"Cache-Control": "public, max-age=3600" // 设置缓存控制头 | |
}) | |
res.end(data) // 返回文件内容 | |
} | |
}) | |
} | |
// 处理动态资源 | |
if (url.startsWith('/api')) { | |
//... 处理动态资源的逻辑 | |
} | |
}) | |
server.listen(80) // 监听端口 80 |
# 邮件服务
邮件服务可以用于给成员发送邮件、通知成员信息,在 node.js 上创建邮件服务,需要提供授权码。
工具:
- js-yaml:用于将 yaml 转为 js 对象
- nodemailer:用于创建邮件服务
使用:
//node.js 发送邮件 | |
const yamlTrans = require('js-yaml'); | |
const fs = require('fs'); | |
const nodemailer = require('nodemailer') | |
const yamlCode = fs.readFileSync('./data.yaml','utf-8'); | |
const dataObj = yamlTrans.load(yamlCode); | |
//nodemailer.createTransport 创建 transPort 服务,传入 auth 信息和配置项 | |
// 授权码需要到对应官网生成 | |
const transPort = nodemailer.createTransport({ | |
serviece:'qq', | |
port:587, | |
host:'smtp.qq.cmo', | |
secure:true, | |
auth:{ | |
pass:dataObj.pass, // 授权码需要去官网申请生成 | |
user:dataObj.user | |
} | |
}) | |
//sendMail 方法发送邮件,传入接收方信息 | |
transPort.sendMail({ | |
to: send.qq.com, | |
from: dataObj.user, | |
subject: '邮件标题', | |
text: '邮件内容' | |
}) |
# 防盗链
防盗链是指在网页或其他资源中,通过直接链接的方式链接到其他网站上的图片、视频或者其他媒体文件,显示在自己的网页上,这种行为通常会给被链接的网站带来额外的带宽消耗和资源浪费,而且可能侵犯了原始网站的版权。采用措施有:
- 通过 HTTP 引用检查:(查看请求来源地址,不匹配则不提供资源)
- 使用 Referrer 检查:检查 HTTP 请求中的 Referrer 字段,该字段指示了请求资源的来源页面(不匹配则不提供服务)
- 使用访问控制列表(ACL):网站管理员可以配置服务器的访问控制列表,只允许特定的域名或 IP 地址访问资源,其他来源的请求将被拒绝。
- 使用防盗链插件或脚本:一些网站平台和内容管理系统提供了专门的插件或脚本来防止盗链。这些工具可以根据需要配置,阻止来自未经授权的网站的盗链请求。
- 使用水印技术:在图片或视频上添加水印可以帮助识别盗链行为,并提醒用户资源的来源。
import express from 'express'; | |
const app = express(); | |
const whitelist = ['localhost']; | |
// 防盗链中间件 | |
const preventHotLinking = (req,res,next)=>{ | |
const referer = req.get('referer'); // 请求中的 referrer 字段标识请求来源 | |
if(referer){ | |
const {hostname} = new URL(referer); | |
if(!whistlist.includes(hostname)){ | |
res.status(403).send('我不允许你访问我的资源'); | |
return; | |
} | |
} | |
next(); | |
}; | |
app.use(preventHotLinking); | |
app.listen(3000,()=>{ | |
console.log('3000端口启动') | |
}) |
# 响应头和请求头
响应头:
HTTP 响应头(HTTP response headers)是在 HTTP 响应中发送的元数据信息,用于描述响应的特性、内容和行为。他们以键值对的形式出现。每个键值对由一个标头字段和响应值组成。
Access-Control-Allow-Origin: *Cache-Control:public, max-age=0, must-revalidateContent-Type:text/html; charset=utf-8Server:nginxDate:Mon, 08 Jan 2024 18:32:47 GMT
cors:
跨域资源共享(CORS)是一种机制,用于在浏览器中实现跨域请求访问资源的权限控制。
当一个网页通过 XMLHttpRequest 或者 Fetch Api 进行跨域请求时,浏览器会根据同源策略进行限制。
同源策略要求请求的协议、域名和端口号必须一致。
请求头:
Accept:指定客户端能够处理的内容类型。
Accept-Language:指定客户端偏好的自然语言。
Content-Language:指定请求或响应实体的自然语言。
Content-Type:指定请求或响应实体的媒体类型。
DNT (Do Not Track):指示客户端不希望被跟踪。
Origin:指示请求的源(协议、域名和端口)。
User-Agent:包含发起请求的用户代理的信息。
Referer:指示当前请求的源 URL。
Content-type: application/x-www-form-urlencoded | multipart/form-data | text/plain
请求方法支持:
服务端默认只支持 GET、POST、HEAD、OPTIONS 请求,使用其他 restful api 请求方法需要添加响应头 Access-Control-Allow-Methods: *
# SSE
SSE(Server-Sent-Events)是一种在客户端和服务器之间实现单向事件流的机制,允许服务器主动向客户端发送事件数据,在 SSE 中可以自定义事件来完成。
SSE 核心就是:
- 前端通过
EventSource来注册事件源,监听对应事件。 - 后端通过设置响应头
Content-Type为:text/event-stream之后 发送具有特定类型的事件数据。
- 前端通过
前端:
const sse = new EventSource('http://localhost:3000/sse'); | |
sse.addEventListener('test',(event)=>{ | |
console.log(event.data); | |
}) |
后端:
app.get('/sse'(req,res)=>{ | |
res.setHeader('Content-Type','text/event-stream'); // 设置事件响应头 | |
res.status(200); | |
setInterval(()=>{ | |
res.write('event: test\n'); // 发送对应的事件 | |
res.write('data: ' + new Date().getTime() + '\n\n'); | |
},1000) | |
}) |
# ORM 框架
- ORM (Object Relation Map):对象关系映射,常用于为关系型数据库提供类型安全的支持。
# knex
- knex 是一个基于 JavaScript 的查询生成器
- knex 允许使用 JavaScript 代码来生成和执行 SQL 查询语句
- knex 提供了一种简单和直观的方式来与关系型数据库进行交互,而无需编写 SQL 语句
- 可以使用 knex 来定义表结构,执行查询、插入、更新和删除等操作。
连接数据库:
import knex from 'knex'; | |
const db = knex({ | |
client: "mysql2", | |
connection:{ | |
user:root, | |
password:'123456', | |
host:localhost, | |
port:3306, | |
database:test | |
} | |
}) |
增删改查详见官网。
事务:
事务相当于分组的一个概念,可以使用事务来确保一组数据库操作的原子性,要么全部成功提交,要么全部回滚。
# prisma
Prisma 和 Knex 都是现代的 Node.js ORM(对象关系映射)库,它们可以帮助开发者以面向对象的方式来操作数据库。尽管它们的目标相似,但它们在设计理念、功能特性和使用方式上存在一些区别:
- prisma 和 TypeScript 联系紧密
- prisma 提供强大的类型安全
prisma CLI
prisma 对应的脚手架可以快速创建模板结构。
# 设计模式
# MVC
概念:
MVC 是一种常用的软件架构模式,用于设计和组织应用程序的代码
它将应用程序分为三个主要的组件:模型 (Model)、视图 (view) 和控制器 (Controller),各自负责不同的模块
作用:
- MVC 将应用程序的逻辑数据等和界面相分离,以提高代码的可维护性、可扩展性和可重用性。
- 通过将不同职责分配给不同组件,MVC 提供了一种清晰的结构使得开发人员更好的管理应用程序的各个部分
# loC 控制反转
概念:
控制反转(IoC)是一种设计原则,它将组件的控制权从组件自身转移到外部容器。
传统上,组件负责自己的创建和管理,而控制反转则将这个责任转给了一个外部的容器或框架。容器负责创建组件实例并管理它们的生命周期,组件只需声明自己所需的依赖关系,并通过容器获取这些依赖。
loC 控制反转使得组件更加松耦合、可测试和可维护。
依赖注入:
依赖注入(DI)是实现控制反转的一种具体技术。
它通过将组件的依赖关系从组件内部移动到外部容器来实现松耦合。
组件不再负责创建或管理它所依赖的其他组件,而是通过构造函数、属性或方法参数等方式将依赖关系注入到组件中。
依赖注入可以通过构造函数注入(Constructor Injection)、属性注入(Property Injection)或方法注入(Method Injection)等方式实现。
工具包:
可以使用 inversify、reflect-metadata、inversify-express-utils 来实现。
# JWT
介绍:
JWT(JSON Web Token)是一种开放的标准,是一种基于 JSON 的安全令牌,用于在客户端和服务端之间传输信息。
组成:
JWT 由三部分组成,它们通过点(.)进行分隔:
- Header(头部):包含了令牌的类型和使用的加密算法等信息。通常采用 Base64 编码表示。
- Payload(负载):包含了身份验证和授权等信息,如用户 ID、角色、权限等。也可以自定义其他相关信息。同样采用 Base64 编码表示。
- Signature(签名):使用指定的密钥对头部和负载进行签名,以确保令牌的完整性和真实性。
工作流程:
- 用户通过提供有效的凭证(例如用户名和密码)进行身份验证。
- 服务器验证凭证,并生成一个 JWT 作为响应。JWT 包含了用户的身份信息和其他必要的数据。
- 服务器将 JWT 发送给客户端。
- 客户端在后续的请求中,将 JWT 放入请求的头部或其他适当的位置。
- 服务器在接收到请求时,验证 JWT 的签名以确保其完整性和真实性。如果验证通过,服务器使用 JWT 中的信息进行授权和身份验证。
# Redis
内存存储系统
介绍:
Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,提供了一个高效的键值存储解决方案,并支持多种数据结构,如:string 字符串、hashes 哈希、lists 列表、sets 集合和 sorted sets 有序集合等等。
应用:
Redis 被广泛应用于缓存、消息队列和实时统计等场景。
特点:
- 内存存储,因此具有快速的读写功能,能持久化数据到硬盘,以便在重新启动后恢复数据
- 多种数据结构,Redis 支持多种数据结构
- 发布 / 订阅,Redis 支持发布订阅模式,允许多个客户端订阅同一个或多个频道,以接收实时发布的消息,这使得 Redis 可以用于实时消息系统
- 事务支持,Redis 支持事务,可以将多个命令打包成一个原子操作执行,确保命令要么全部成功,要么全部失败
- 持久化,Redis 提供两种持久化数据的方式:
- RDB(Redis Database),RDB 是将数据以快照的形式保存到磁盘。
- AOF(Append Only File),AOF 是将每个写操作追加到文件中,确保数据在意外宕机或重启后的持久性
- 高可用性,Redis 支持主从复制和 Sentine 哨兵机制,通过主从复制可以创建多个 Redis 实例的副本,以提高读取性和容错能力。
sentinel是一个用于监控和自动故障转移的系统,可以在主节点宕机时自动将节点提升为主节点。 - 缓存,Redis 的快速读写能力和灵活的数据结构使其被广泛应用于缓存层,它可以将常用的数据存储在内存中,以加快数据访问速度,减轻后端数据库的负载。
- 实时统计,Redis 的计数器和有序集合等数据结构使其非常适合实时统计的场景,可以存储和更新计数器,并对有序集合进行排名和范围查询,用于统计和排行榜功能。
安装
安装文件,配置环境变量,然后启动即可。
连接 redis 服务可以使用 Navicate 或者在 vscode 中下载对应的插件。
发布订阅模式:
在 redis 中,发布订阅模式通过命令:publish、subscribe、unsubscribe、psubscribe 命令和 punsubscribe 命令来进行操作。
事务:
- redis 支持事务,允许用户将多个命令打包在一起作为一个单元进行执行,事务提供了一种原子性操作的机制,要么所有命令都执行成功,要么所有命令都不成功。
- Redis 的事务不支持回滚操作,如果在事务执行期间发生错误,事务会继续执行,而不会会回滚已执行的命令。
- Redis 事务常用命令:
- multi:开启一个事务
- exec:执行事务中所有命令
- watch:对一个或多个键进行监视
- discard:取消事务,清空事务队列中的命令。
redis 持久化:
- RDB(Redis Database)持久化
- RDB 持久化是一种快照的形式,会将内存中的数据定期保存到磁盘上。
- 可以通过配置 Redis 服务器,设置自动触发 RDB 快照的条件,比如指定时间间隔或指定操作次数自动保存。
- RDB 持久化生成的快照文件是二进制文件,包含了 Redis 数据的完整状态。
- 在恢复数据时,可以通过加载快照文件将数据重新加载到内存中。
- RDB 使用:
- 找到 redis 的 redis.conf 文件,配置其中的 save 字段。
- 或者在 redis 启动的命令行中输入 save,手动保存快照。
- AOF(Append Only File)持久化
- AOF 持久化记录了 Redis 服务器执行的所有写操作命令,在文件中以追加的方式保存
- 当 redis 重启时,可以重新执行 AOF 文件中保存的命令,以重新构建数据集。相比于 RDB 持久化,AOF 持久化提供了更好的数据恢复保证,因为它记录了每个写操作,而不是快照的形式。
- AOF 文件相对于 RDB 文件更大,恢复数据的速度可能会比较慢。
- AOF 使用:
- redus.conf 文件的 appendonly 字段设置为 yes。
redis 主从复制:
- redis 主从复制是一种数据复制和同步机制,其中一个 redis 服务器(主服务器)将其数据复制到一个或多个其他 Redis 服务器(从服务器)中,主从复制提供了数据冗余备份、读写分离和故障恢复等功能。
ioredis:在 node.js 中与 Redis 进行交互的三方库。
# lua
轻量级、可嵌入的脚本语言。
介绍:
- lua 是一种轻量级、高效、可嵌入的脚本语言,被广泛应用于嵌入式系统、游戏开发、Web 应用和脚本编写等领域。
- 其设计目标之一就是作为扩展和嵌入式脚本语言,可以与其他编程语言无缝集成。
- 在 redius 中可以直接执行 lua 脚本(.lua 文件)。
- web 应用为了增强性能和可扩展性,通常将 Lua、Redis 和 Nginx 结合使用,以构建高性能的 Web 应用程序或 API 服务。
安装
# corn 表达式
corn 表达式是一种用汉语指定定时任务执行时间的字符串表示形式,由 6 个或 7 个字段组成,每个字段表示任务执行的时间单位和范围。
格式为:
* * * * * * | |
┬ ┬ ┬ ┬ ┬ ┬ | |
│ │ │ │ │ │ | |
│ │ │ │ │ └── 星期(0 - 6,0表示星期日) | |
│ │ │ │ └───── 月份(1 - 12) | |
│ │ │ └────────── 日(1 - 31) | |
│ │ └─────────────── 小时(0 - 23) | |
│ └──────────────────── 分钟(0 - 59) | |
└───────────────────────── 秒(0 - 59) |
常见的 Cron 表达式示例:
* * * * * *:每秒执行一次任务。0 * * * * *:每分钟的整点执行一次任务。0 0 * * * *:每小时的整点执行一次任务。0 0 * * * *:每天的午夜执行一次任务。0 0 * * 1 *:每周一的午夜执行一次任务。0 0 1 * * *:每月的 1 号午夜执行一次任务。0 0 1 1 * *:每年的 1 月 1 日午夜执行一次任务。
掘金定时自动签到:
const schedule = require('node-schedule') | |
const axios = require('axios'); | |
const aid = '******' // 输入掘金账号的 aid | |
const uid = '******' // 输入掘金账号的 uid | |
const cookie = '******' // 输入在掘金的 cookie | |
schedule.scheduleJob('48 15 * * *',()=>{ | |
//corn 表达式表示 43 分钟 15 小时每天每月每星期(每天 15 点 43 分)点执行 | |
axios.post(`https://api.juejin.cn/growth_api/v1/check_in?aid=${aid}&uid=${uid}`,{},{ | |
headers:{ | |
referer: 'https://juejin.cn/', | |
cookie: `sessionid=${}` | |
} | |
}).then(res=>{ | |
console.log('签到成功'); | |
}).catch(err=>{ | |
console.log('出现错误',err); | |
}) | |
}) |
# serverLess
介绍:
- serverLess 并不是一项技术,而是一个架构模型(无服务器架构)。
- 在传统模式下,部署一个服务需要选择服务器(linux、windows 等),并且需要安装环境,熟悉操作系统命令,知晓安全知识等,都需要一定的成本,serverLess 的核心思想就是让开发者更多关注业务本身而不是服务器运行成本。
Faas:函数即服务
FaaS 是一种 Serverless 计算模型,它允许开发人员编写和部署函数代码,而无需关心底层的服务器管理。在 FaaS 中,开发人员只需关注函数的实现和逻辑,将其上传到云平台上,平台会负责函数的运行和扩展。当有请求触发函数时,云平台会自动为函数提供所需的计算资源,并根据请求量进行弹性扩展。这种按需计算的模式使开发人员可以更专注于业务逻辑的实现,同时实现了资源的高效利用。
每个函数即一个服务,函数内只需处理业务,可以使用 BASS 层提供的服务已完成业务,无需关心背后计算资源的问题。
Baas:后端即服务
后端即服务是一种提供面向移动应用和 Web 应用的后端功能的云服务模型。BaaS 为开发人员提供了一组预构建的后端服务,如用户身份验证、数据库存储、文件存储、推送通知等,以简化应用程序的开发和管理。开发人员可以使用 BaaS 平台提供的 API 和 SDK,直接集成这些功能到他们的应用中,而无需自己构建和维护后端基础设施。
对后端的资源当成一种服务,如文件存储,数据存储,推送服务,身份验证。该层只需提供对应的服务,无需关心业务。定义为底层基础服务,由其他服务调用,正常不触及用户终端。
脚手架快速编写:https://www.npmjs.com/package/@serverless-devs/s
# webSocket
传统 HTTP 的不足:
传统 HTTP 是一种单向请求 -- 响应协议,客户端发送请求之后,服务器才会响应并返回相应的数据。
在传统 HTTP 中,客户端需要主动发送请求才能获取服务器上的资源,而且每次请求都需要重新建立连接,这种方式在实时通信和持续获取资源的场景下效率较低。
Socket:
socket 提供了实时的双向通信能力,可以实时地传输数据。客户端和服务器之间的通信是即时的,数据的传输和响应几乎是实时完成的,不需要轮询或定时发送请求。
node 中使用 webSocket:
- 客户端:
<!DOCTYPE html> | |
<html lang="en"> | |
<head> | |
<meta charset="UTF-8"> | |
<meta name="viewport" content="width=device-width, initial-scale=1.0"> | |
<title>Document</title> | |
<style> | |
* { | |
padding: 0; | |
margin: 0; | |
} | |
html, | |
body, | |
.room { | |
height: 100%; | |
width: 100%; | |
} | |
.room { | |
display: flex; | |
} | |
.left { | |
width: 300px; | |
border-right: 0.5px solid #f5f5f5; | |
background: #333; | |
} | |
.right { | |
background: #1c1c1c; | |
flex: 1; | |
display: flex; | |
flex-direction: column; | |
} | |
.header { | |
background: #8d0eb0; | |
color: white; | |
padding: 10px; | |
box-sizing: border-box; | |
font-size: 20px; | |
} | |
.main { | |
flex: 1; | |
padding: 10px; | |
box-sizing: border-box; | |
font-size: 20px; | |
overflow: auto; | |
} | |
.main-chat { | |
color: green; | |
} | |
.footer { | |
min-height: 200px; | |
border-top: 1px solid green; | |
} | |
.footer .ipt { | |
width: 100%; | |
height: 100%; | |
color: green; | |
outline: none; | |
font-size: 20px; | |
padding: 10px; | |
box-sizing: border-box; | |
} | |
.groupList { | |
height: 100%; | |
overflow: auto; | |
} | |
.groupList-items { | |
height: 50px; | |
width: 100%; | |
background: #131313; | |
display: flex; | |
align-items: center; | |
justify-content: center; | |
color: white; | |
} | |
</style> | |
</head> | |
<div class="room"> | |
<div class="left"> | |
<div class="groupList"> | |
</div> | |
</div> | |
<div class="right"> | |
<header class="header">聊天室</header> | |
<main class="main"> | |
</main> | |
<footer class="footer"> | |
<div class="ipt" contenteditable></div> | |
</footer> | |
</div> | |
</div> | |
<body> | |
<script type="module"> | |
const sendMessage = (message) => { | |
const div = document.createElement('div'); | |
div.className = 'main-chat'; | |
div.innerText = `${message.user}:${message.text}`; | |
main.appendChild(div) | |
} | |
const groupEl = document.querySelector('.groupList'); | |
const main = document.querySelector('.main'); | |
import { io } from "https://cdn.socket.io/4.7.4/socket.io.esm.min.js"; | |
const name = prompt('请输入你的名字'); | |
const room = prompt('请输入房间号'); | |
const socket = io('ws://localhost:3000'); | |
// 键盘按下发送消息 | |
document.addEventListener('keydown', (e) => { | |
if (e.key === 'Enter') { | |
e.preventDefault(); | |
const ipt = document.querySelector('.ipt'); | |
socket.emit('message', { | |
text: ipt.innerText, | |
room: room, | |
user: name | |
}); | |
sendMessage({ | |
text: ipt.innerText, | |
user: name, | |
}) | |
ipt.innerText = ''; | |
} | |
}) | |
// 连接成功 socket | |
socket.on('connect', () => { | |
socket.emit('join', { name, room });// 加入一个房间 | |
socket.on('message', (message) => { | |
sendMessage(message) | |
}) | |
socket.on('groupList', (groupList) => { | |
console.log(groupList); | |
groupEl.innerHTML = '' | |
Object.keys(groupList).forEach(key => { | |
const item = document.createElement('div'); | |
item.className = 'groupList-items'; | |
item.innerText = `房间名称:${key} 房间人数:${groupList[key].length}` | |
groupEl.appendChild(item) | |
}) | |
}) | |
}) | |
</script> | |
</body> | |
</html> |
- 服务端:
import http from 'http' | |
import { Server } from 'socket.io' | |
import express from 'express' | |
const app = express() | |
app.use('*', (req, res, next) => { | |
res.setHeader("Access-Control-Allow-Origin", "*"); | |
res.setHeader("Access-Control-Allow-Headers", "*"); | |
res.setHeader("Access-Control-Allow-Methods", "*"); | |
next(); | |
}) | |
const server = http.createServer(app) | |
const io = new Server(server, { | |
cors: true // 允许跨域 | |
}) | |
const groupList = {} | |
/** | |
* [{1008:[{name,room,id}]}] | |
*/ | |
io.on('connection', (socket) => { | |
// 加入房间 | |
socket.on('join', ({ name, room }) => { | |
socket.join(room) | |
if (groupList[room]) { | |
groupList[room].push({ name, room, id: socket.id }) | |
} else { | |
groupList[room] = [{ name, room, id: socket.id }] | |
} | |
socket.emit('message', { user: '管理员', text: `${name}进入了房间` }) | |
socket.emit('groupList', groupList) | |
socket.broadcast.emit('groupList', groupList) | |
}) | |
// 发送消息 | |
socket.on('message', ({ text, room, user }) => { | |
socket.broadcast.to(room).emit('message', { | |
text, | |
user | |
}) | |
}) | |
// 断开链接内置事件 | |
socket.on('disconnect', () => { | |
Object.keys(groupList).forEach(key => { | |
let leval = groupList[key].find(item => item.id === socket.id) | |
if (leval) { | |
socket.broadcast.to(leval.room).emit('message', { user: '管理员', text: `${leval.name}离开了房间` }) | |
} | |
groupList[key] = groupList[key].filter(item => item.id !== socket.id) | |
}) | |
socket.broadcast.emit('groupList', groupList) | |
}) | |
}); | |
server.listen(3000, () => { | |
console.log('listening on :3000'); | |
}); |
# 爬虫
介绍:
- 爬虫也称为网络爬虫或网络蜘蛛,是指一种自动化程序或脚本,用于在互联网上浏览和提取信息。
- 爬虫模拟人类在网页上的行为,通过 HTTP 协议发送请求,获取网页内容,然后解析并提取需要的内容。
- 在 node 中使用爬虫需要借助模拟浏览器环境的包(如 puppeteer)来模拟浏览器环境。
工具:
- puppeteer(模拟浏览器环境)
使用:
npm 包:
npm i puppeteer |
index.js:
import puppeteer from "puppeteer"; | |
const btnText = process.argv[2]; | |
const browser = await puppeteer.launch({ | |
headless:false, // 取消无头模式 | |
}) | |
const page = await browser.newPage(); // 打开一个页面 | |
console.log(page); | |
page.setViewport({ width:1920,height:1080 }); // 设置页面宽高 | |
await page.goto('https://juejin.cn/'); // 跳转 | |
await page.waitForSelector('.side-navigator-wrap'); // 等待元素出现 | |
const elements = await page.$$('.side-navigator-wrap .nav-item-wrap span') // 获取元素 | |
const articleList = []; | |
const collectFunc = async()=>{ | |
await page.waitForSelector('.entry-list') | |
const elements = await page.$$('.entry-list .title-row a') | |
for await (let el of elements) { | |
const text = await el.getProperty('innerText') | |
const name = await text.jsonValue() | |
articleList.push(name) | |
} | |
console.log(articleList) | |
} | |
for await (let el of elements) { | |
const text = await el.getProperty('innerText') // 获取 span 的属性 | |
const name = await text.jsonValue() // 获取内容 | |
if (name.trim() === (btnText || '前端')) { | |
await el.click() // 自动点击对应的菜单 | |
collectFunc() // 调用函数 | |
} | |
} |
可以结合 node 子进程跑 python 脚本,使用 pip 仓库中相应的包和功能。
# C++ 扩展
Node.js 在 IO 方面具有极强的能力,但是对 CPU 密集型的任务有所不足,为了填补这部分缺点,node.js 支持 C/C++ 为其编写原生的 nodejs 插件,补充这方面能力。
node.js 中 C++ 扩展:
c++ 编写的代码能够被编译成一个动态链接库 (dll), 可以被 nodejs require 引入使用,后缀是 .node
.node 文件的原理就是 ( window dll ) ( Mac dylib ) ( Linux so )
c++ 扩展编写语法
NAN (Native Abstractions for Nodejs) 一次编写,到处编译
- 因为 Nodejs 和 V8 都更新的很快所有每个版本的方法名也不一样,对我们开发造成了很大的问题例如
- 0.50 版本
Echo(const Prototype&proto) - 3.00 版本
Echo(Object<Prototype>& proto)
NAN 的就是一堆宏判断,判断各种版本的 API,用来实现兼容所以他会到处编译
- N-API (node-api) 无需重新编译
- 基于 C 的 API
- c++ 封装 node-addon-api
N-API 是一个更现代的选择,它提供了一个稳定的、跨版本的 API,使得你的插件可以在不同版本的 Node.js 上运行,而无需修改代码。这大大简化了编写和维护插件的过程。
对于 C++,可以使用 node-addon-api,这是 N-API 的一个封装,提供了一个更易于使用的 C++ API。这将使你的代码更易于阅读和维护。
使用场景
- 使用 C++ 编写的 Nodejs 库如
node-sassnode-jieba等 - CPU 密集型应用
- 代码保护
需要安装 C++ 编辑器:
npm install --global --production windows-build-tools #管理员运行 | |
#如果安装过 python 以及 c++ 开发软件就不需要装这个了 | |
npm install node-gyp -g #全局安装 | |
npm install node-addon-api -D #装到项目里 |
使用:
cpu.cpp:
#define NAPI_VERSION 3 //指定addon版本
#define NAPI_CPP_EXCEPTIONS //启用 Node.js N-API 中的 C++ 异常支持
#include <napi.h> //addon API
#include <windows.h> //windwos API
Napi::Value GetScreenSize(const Napi::CallbackInfo& info) {
Napi::Env env = info.Env(); //指定环境
int cx = GetSystemMetrics(SM_CXSCREEN); //获取设备宽
int cy = GetSystemMetrics(SM_CYSCREEN); //获取设备高
Napi::Object result = Napi::Object::New(env); //创建一个对象
result.Set("width", cx);
result.Set("height", cy);
return result; //返回对象
}
Napi::Object Init(Napi::Env env, Napi::Object exports) {
//抛出一个函数 getScreenSize
exports.Set("getScreenSize", Napi::Function::New(env, GetScreenSize));
return exports;
}
//addon固定语法 必须抛出这个方法
NODE_API_MODULE(NODE_GYP_MODULE_NAME, Init)
binding.gyp:
{ | |
"targets":[ | |
{ | |
"target_name": "cpu", //名称 | |
"sources": [ "cpu.cpp" ], //指定文件 | |
"include_dirs": [ | |
"<!@(node -p \"require('node-addon-api').include\")" //引入addon | |
] | |
} | |
] | |
} |
index.js:
const addon = require('./build/Release/cpu.node') | |
console.log(addon.getScreenSize()) |
命令行中打包 addon:
node-gyp configure #生成配置文件 | |
node-gyp build #打包 addon |
# 大文件上传
大文件上传方案:
- 大文件分片:将大文件切分成较小的片段(通常称为分片或者块),然后逐个上传这些分片
- 优点是:提高上传的稳定性,因为上传失败时只需要重新上传该分片而不需要重新上传整个文件,同时分片上传还可以利用多个网络连接并行上传多个分片,提高上传速度。
- 断点续传:如果上传中止,断点传输可以记录已成功上传的分片信息,以便在恢复上传时继续上传未完成的任务,而不是重新上传整个文件
- 优点是可以大大减少上传失败的影响,并节省时间和带宽。
前端:
<script> | |
const fileDOM = document.getElementById('file'); | |
fileDOM.addEventListener('change',(e)=>{ | |
const file = e.target.files[0]; | |
// 对文件进行分片 | |
const chunks = sliceFile(file); | |
// 上传分片数据 | |
postChunksData(chunks); | |
}) | |
function sliceFile(file,size=1024 * 1024 * 4) { | |
const chunks = []; | |
for(let i=0;i<file.size;i+=size){ | |
chunks.push(file.slice(i , i + size)); | |
} | |
return chunks; | |
} | |
function postChunksData(chunks) { | |
const list = []; | |
for(let i=0;i<chunks.length;i++){ | |
// 使用 formData 上传所有分片 | |
const formData = new FormData(); | |
formData.append('index',i); | |
formData.append('total',chunks.length); | |
formData.append('fileName','分片文件'); | |
formData.append('file',chunks[i]); | |
list.push(fetch('http://localhost:3000/up',{ | |
method:'POST', | |
body: formData, | |
})) | |
} | |
// 上传完所有分片之后将文件合并 | |
Promise.all(list).then(res => { | |
fetch('http://localhost:3000/merge',{ | |
method:"POST", | |
headers:{ | |
"Content-Type":"application/json" | |
}, | |
body:JSON.stringify({ | |
fileName:"分片上传文件", | |
}) | |
}).then(res=>{ | |
console.log(res); | |
}) | |
}) | |
} | |
</script> |
服务端:
import express from 'express' | |
import multer from 'multer' | |
import cors from 'cors' | |
import fs from 'node:fs' | |
import path from 'node:path' | |
const storage = multer.diskStorage({ | |
destination: (req, file, cb) => { | |
cb(null, 'uploads/') | |
}, | |
filename: (req, file, cb) => { | |
cb(null, `${req.body.index}-${req.body.fileName}`) | |
} | |
}) | |
const upload = multer({ storage }) | |
const app = express() | |
app.use(cors()) | |
app.use(express.json()) | |
// 使用 multer 将数据存到服务器磁盘中 | |
app.post('/up', upload.single('file'), (req, res) => { | |
res.send('ok') | |
}) | |
// 使用 fs.appendFileSync 将切片文件进行合成 | |
app.post('/merge', async (req, res) => { | |
const uploadPath = './uploads' | |
let files = fs.readdirSync(path.join(process.cwd(), uploadPath)) | |
files = files.sort((a, b) => a.split('-')[0] - b.split('-')[0]) | |
const writePath = path.join(process.cwd(), `video`, `${req.body.fileName}.mp4`) | |
files.forEach((item) => { | |
fs.appendFileSync(writePath, fs.readFileSync(path.join(process.cwd(), uploadPath, item))) | |
fs.unlinkSync(path.join(process.cwd(), uploadPath, item)) | |
}) | |
res.send('ok') | |
}) | |
app.listen(3000, () => { | |
console.log('Server is running on port 3000') | |
}) |
# 文件流下载
文件流下载是一种将文件内容通过流的形式发送给客户端,实现文件下载的方法,适用于处理大型文件或者需要实时生成文件内容的情况。
核心知识响应头:
- Content-Type 指定下载文件的 MIME 类型
application/octet-stream(二进制流数据)application/pdf:Adobe PDF 文件。application/json:JSON 数据文件image/jpeg:JPEG 图像文件
Content-Disposition指定服务器返回的内容在浏览器中的处理方式。它可以用于控制文件下载、内联显示或其他处理方式attachment:指示浏览器将响应内容作为附件下载。通常与filename参数一起使用,用于指定下载文件的名称inline:指示浏览器直接在浏览器窗口中打开响应内容,如果内容是可识别的文件类型(例如图片或 PDF),则在浏览器中内联显示
- Content-Type 指定下载文件的 MIME 类型
前端:
<script> | |
const btn = document.getElementById('btn') | |
btn.onclick = () => { | |
fetch('http://localhost:3000/download',{ | |
method:"post", | |
body:JSON.stringify({ | |
fileName:'1.png' | |
}), | |
headers:{ | |
"Content-Type":"application/json" | |
} | |
}).then(res=>res.arrayBuffer()).then(res=>{ // 请求到 stream 流式数据后,通过 res.arrayBuffer 方法获得 Buffer 数据,用 Blob 容器存储二进制缓冲数据,通过 URL.createObjectURL 创建 URL 地址,赋给 a 标签进行下载。 | |
const blob = new Blob([res],{type:'image/png'}) | |
const url = URL.createObjectURL(blob) | |
const a = document.createElement('a') | |
a.href = url | |
a.download = '1.png' | |
a.click() | |
}) | |
} | |
</script> |
服务端:
import express from 'express' | |
import fs from 'fs' | |
import path from 'path' | |
import cors from 'cors' | |
const app = express() | |
app.use(cors()) | |
app.use(express.json()) | |
app.use(express.static('./static')) | |
app.post('/download', function (req, res) { // 当请求 download 路径时,通过 fs 读取文件数据,设置响应头后返回文件数据 | |
const fileName = req.body.fileName | |
const filePath = path.join(process.cwd(), './static', fileName) | |
const content = fs.readFileSync(filePath) | |
res.setHeader('Content-Type', 'application/octet-stream') | |
res.setHeader('Content-Disposition', 'attachment;filename=' + fileName) | |
res.send(content) | |
}) | |
app.listen(3000, () => { | |
console.log('http://localhost:3000') | |
}) |
# HTTP 缓存
HTTP 缓存分为两大类:强缓存和协商缓存。这两种缓存都是通过 HTTP 响应头来控制,目的是提高网站的性能。
# 缓存策略
- 强缓存
强缓存之后则不需要重新向服务器发送请求,而是从浏览器缓存(内存缓存或者硬盘缓存中)读取。
- memory cache (内存缓存) 内存缓存存储在浏览器内存当中,一般刷新网页的时候会发现很多内存缓存
- disk cache (硬盘缓存) 硬盘缓存是存储在计算机硬盘中,空间大,但是读取效率比内存缓存慢
强缓存设置需要服务端设置对应的响应头 Cache-Control,响应头含义如下:
max-age:浏览器资源缓存的时长 (秒)。no-cache:不走强缓存,走协商缓存。no-store:禁止任何缓存策略。public:资源即可以被浏览器缓存也可以被代理服务器缓存 (CDN)。private:资源只能被客户端缓存。
const express = require('express'); | |
const app = express(); | |
app.get('/',(req,res)=>{ | |
res.setHeader('Cache-Control','public, max-age=20'); | |
res.json({ | |
name:"cache", | |
version:'1.0.0' | |
}) | |
}); | |
app.listen(3000,()=>{ | |
console.log('服务启动') | |
}) |
协商缓存
当涉及到缓存机制时,强缓存优先于协商缓存。当资源的强缓存生效时,客户端可以直接从本地缓存中获取资源,而无需与服务器进行通信。
如果强缓存未命中(例如
max-age过期),或者服务器响应中设置了Cache-Control: no-cache,则客户端会发起协商缓存的请求。在协商缓存中,客户端会发送带有缓存数据标识的请求头部字段,以向服务器验证资源的有效性。服务器会根据客户端发送的协商缓存字段(如
If-Modified-Since和If-None-Match)来判断资源是否发生变化。如果资源未发生修改,服务器会返回状态码 304(Not Modified),通知客户端可以使用缓存的版本。如果资源已经发生变化,服务器将返回最新的资源,状态码为 200。服务端通过设置响应头
Last-Modified和If-Modified-Since来通知客户端最后修改时间,客户端在后续请求中通过If-Modified-Since请求头携带该时间,服务器判断资源是否有更新,如何没有返回 304 状态码。
import express from 'express' | |
import cors from 'cors' | |
import fs from 'node:fs' | |
const getModifyTime = () => { | |
return fs.statSync('./index.js').mtime.toISOString() // 获取文件最后修改时间 | |
} | |
const app = express() | |
app.use(cors()) | |
app.get('/api', (req, res) => { | |
res.setHeader('Cache-Control', 'no-cache, max-age=2592000')// 表示走协商缓存 | |
const ifModifiedSince = req.headers['if-modified-since'] // 获取浏览器上次修改时间 | |
res.setHeader('Last-Modified', getModifyTime()) | |
if (ifModifiedSince && ifModifiedSince === getModifyTime()) { | |
console.log('304') | |
res.statusCode = 304 | |
res.end() | |
return | |
} else { | |
console.log('200') | |
res.end('value') | |
} | |
}) | |
app.listen(3000, () => { | |
console.log('Example app listening on port 3000!') | |
}) |
# HTTP 缓存字段
- Cache-Control 指定缓存时长
- Expires 指定过期时间
- ETag/If-None-Match
ETag 和 If-None-Match:服务器通过 ETag 响应头给资源生成一个唯一标识符。客户端在后续请求中通过 If-None-Match 请求头携带该标识符,服务器根据标识符判断资源是否有更新。如果没有更新,返回 304 状态码。
ETag 优先级比 Last-Modified 高
- Last-Modified/If-Modified-Since
检查客户端发送的 if-modified-Since 头,如果请求的 If-Modified-Since 大于最后修改时间,就直接返回 304 缓存状态码
# HTTP2
HTTP2 是超文本传输协议的下一个主要版本,是对 HTTP/1.1 协议的重大改进。目标是改善性能、效率和安全性,提供更快更高效的网络通信。
多路复用
HTTP/2 支持在单个 TCP 连接上同时发送多个请求和响应,这意味着可以避免建立多个连接,减少网络延迟,提高效率。
二进制分帧
- 在 HTTP2 应用层和传输层之间增加了二进制分帧层,将请求和响应拆分为多个帧,这种二进制格式的设计使得协议更加高效,并且容易解析和处理。
- 数据帧(Data Frame):用于传输请求和响应的实际数据。
- 头部帧(Headers Frame):包含请求或响应的头部信息。
- 优先级帧(Priority Frame):用于指定请求的优先级。
- 设置帧(Settings Frame):用于传输通信参数的设置。
- 推送帧(Push Promise Frame):用于服务器主动推送资源。
- PING 帧(PING Frame):用于检测连接的活跃性。
- 重置帧(RST_STREAM Frame):用于重置数据流或通知错误。
- 在 HTTP2 应用层和传输层之间增加了二进制分帧层,将请求和响应拆分为多个帧,这种二进制格式的设计使得协议更加高效,并且容易解析和处理。
头部压缩
- HTTP2 采用首部表和动态压缩算法来减少头部的大小,这减少了每个请求和响应的开销,提高了传输效率。
node 中实现
可以使用 openssl 生成 tls 证书:
生成私钥
openssl genrsa -out server.key 1024
生成证书请求文件 (用完可以删掉也可以保留)
openssl req -new -key server.key -out server.csr
生成证书
openssl x509 -req -in server.csr -out server.crt -signkey server.key -days 3650
import http2 from 'node:http2'
import fs from 'node:fs'
const server = http2.createSecureServer({
key: fs.readFileSync('server.key'),
cert: fs.readFileSync('server.crt')
})
server.on('stream', (stream, headers) => {
stream.respond({
'content-type': 'text/html; charset=utf-8',
':status': 200
})
stream.on('error', (err) => {
console.log(err)
})
stream.end(`
<h1>http2</h1>
`)
})
server.listen(80, () => {
console.log('server is running on port 80')
})
# Node 中事件循环
https://www.cnblogs.com/goloving/p/16523648.html
本篇出于学习 node.js 教程后所整理,内容中有大量引用和参照,详细可点击前去了解