# AI
- AI 俗称人工智能,是一种计算机程序,可以模拟人类的思维过程,从而实现某些人类智能的任务
- AI 的目标是理解和构建能够执行通常需要人类智能才能完成的任务的机器,如:学习推理、问题解决、语言理解、知识表示、规划等
# 机器学习
预测函数和损失函数
- 预测函数代表模型训练的规则,损失函数代表数据和训练目标之间的误差,表示该数据是否应该被丢弃
# 线性回归 / 逻辑回归
回归
- 对输入进行预测,预测出某一个具体的值
分类
- 对结果进行分类,划线
线性回归和逻辑回归的算法,就是如何用数学的方式使用损失函数,找到这条线的过程
# K 近邻(KNN)
核心思想是物以类聚,人以群分
- K 近邻的算法就是通过多维向量将数据进行标识,输入的数据会根据算法得到向量值,距离该向量值最近的 K 个元素的分类就是该输入的分类
# 决策树
根据分类的几个关键特征构建一棵树,分类纯度(权重)越高的越接近根节点,最后生成一颗决策树,对输入的数据根据这棵树进行分析决策
- 决策树算法不是预先生成一颗树
# 支持向量机
支持向量机算法要将数据进行分类,做法是将数据都放入到坐标系中,通过算法分析这些向量找出一条最宽的超平面,对数据进行分类
- 支持向量机和线性回归类似,但是支持向量机可以解决线性不可分的问题,具体方法是通过核函数对坐标系升维,实现线性可分。
# 贝叶斯分类
根据某一类事物发生某一个事件的概率,来进行反推,得到发生某些事情的事物是那种分类
# 神经网络
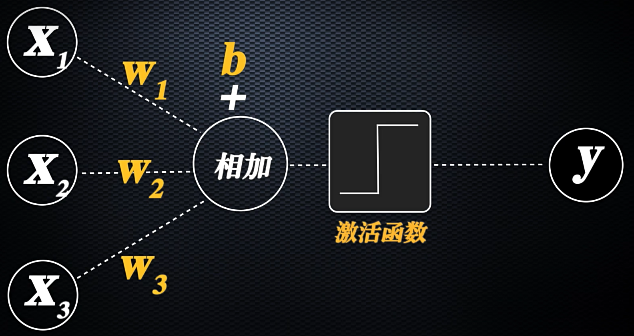
也称为感知机或深度学习,基本思想就是模拟大脑神经元的活动方式来构建预测函数和损失函数,单个感知机的算法机制就是在模拟大脑神经元的运行机制。
- 人脑神经元的轴突用于接收信号,根据信号刺激权重计算阈值,当达到某一个阈值时,传递信号给树突(激活函数)。
- 单个线性机可以解决线性可分问题,但是无法解决线性不可分问题,相比于通过核函数升维,神经网络使用 “加层”
# 深度学习
深度学习就是神经网络在遭遇梯度消失等问题之后的进一步发展
# 加层
- 神经网络之所以称为深度学习就是因为加层,深度学习的深度就是指感知机的层数很多,加层之后的神经网络就能够很好的处理线性不可分的问题
- 对于异或问题,神经网络将异或变为:A⊕B=(A∧¬B)∨(¬A∧B), 第一层先计算括号内的运算,再将数值传入第二层进行运算
- 加层的本质就是线性函数的嵌套,理论上不论多复杂的关系都可以通过多个线程函数将他们的关系拟合出来
# Transformer 大语言模型
# 词的向量化工作
# 向量和向量化
- 将某一个特定的数据,根据其特征意义进行向量标识,存放到一个数组中,用于表示向量,向量的维度越多表示的就越精确。
# 词的向量化
- word2Vec 模型
- 将大量的数据根据特定的规则进行训练,每次计算出与这个特定规则之间的差距,并不断收敛这个值,偏差较大的进行丢弃,最终得到的是一个固定多维分布的坐标系(大模型)。
- 对数据训练时每次都会产生一个随机的 n 维坐标系,需要让该 n 维坐标系满足我们固定的特定规则,差值较大的直接丢弃。
- 词的向量化工作使得电脑可以理解词的含义,每一个词,都被向量的多个维度进行了语义化的对应和标识。
# 收敛
- 模型训练时,通过向量点乘或叉乘获取到值,值越大代表向量越接近,值较小的进行丢弃,这个不断训练矫正的过程就叫收敛。
# 信息压缩和特征词提取
- RNN 循环神经网络、CNN 卷积神经网络
- 图象识别之所以能够在人工智能领域取得突破,就是因为卷积神经网络 CNN 找到了提取图片特征的方法。
# 卷积神经网络 CNN
# Transformer
- Transformer 分为多个模型领域,如:Vision Transformer、CLIP、BERT、GPT、Stable diffusion 等,其中 GPT 通用人工智能最为突出
- 训练规则:多个词语之间通过向量相乘的权重进行关联,权重越高代表词语的相关性越高
- 对模型进行向量化,随机生成 n 维坐标系,输入多个语句进行训练,如果训练偏差较大的进行丢弃,最终得到可以表示语句关联性的 n 维坐标系
Transformer 分为编码器和解码器,编码器用于理解内容(完形填空),解码器用于生成内容(词语接龙)
编码器和解码器相似,都是由一个全连接层和自注意力层所组成,不过解码器还多了一个掩码层(对于词的翻译,由于词的顺序不同,使得后输出的词要在掩码层进行过渡存储)
# 编码器
- 编码器将语言映射成向量
- Google 的 BERT 模型,用于理解内容。
# 解码器
- 解码器再将向量映射为另一种语言。
- OpenAI 的 ChatGPT,用于生成内容,原理就是给出前几个词,推测出后面词的内容,然后添加进去,最后链接成一个句子,ChatGPT 并不具备理解能力,它只会通过前文去进行推测,只不过由于输出量非常庞大,就使得它推测出的是正确结果的概率就更大。
# 自注意力机制
- 原先进行向量化的机制是类似完形填空,填写的不对就重新填写。
- Transformer 模型推出自注意力机制进行词的向量化表示,一举解决了相似度问题,整句语义提取以及跨语言的相似度映射问题
# AI 智能体
- 基于大模型的上一层框架封装,首先他需要拥有记忆,并形成自己的记忆流,然后有自己的规划,如果他有一个目标,那么它会根据自己现有的知识和已有的经验对目标进行分解,将目标分解成一个个的任务,然后按顺序执行它,最后需要有自己的执行能力
- 所有的 AI 框架基本上都是通过已有的大模型的基础之上,增加了这些能力,从而弥补了大模型的不足